
🍪🧾 Générer des PDF dynamiques en Rails : notre approche avec Pdftk
Au programme aujourd’hui :
Remplir un template PDF avec Pdftk. par Stanislas
Temps de lecture : 5 minutes
Hello les petits Biscuits !
Bienvenue sur la 30ème édition de Ruby Biscuit.
Vous êtes maintenant 555 abonnés 🥳
Maintenant Ruby biscuit, c’est aussi votre meilleur allié pour recruter des devs Ruby !
Si vous n’avez pas encore rejoint le club, RDV sur https://recrutement.rubybiscuit.fr
Bonne lecture.
Remplir un template PDF avec Pdftk
Bonjour à tous ! Ce mois-ci nous allons voir comment remplir dynamiquement un template PDF, c'est parti 👇🏻
Mise en place
Nous allons avoir besoin d'installer pdftk sur notre machine, sur lequel se base la gem pdf_forms
Étapes :
1. Installation de pdftk et pdf_forms
2. Configuration à mettre en place
3. Comprendre comment assigner les variables sur le PDF
4. Création d'un dictionary pour assigner les variables
5. Génération du PDF
Pré-requis : Doc PDF avec variables assignées.
1) Installation de pdftk et pdf_forms
→ Installer pdftk sur sa machine avec
brew install pdftk-java Pourquoi suffixer avec java ? Parce homebrew nous le conseille sur Mac à partir du M1 .
⚠️ Par défaut homebrew va vouloir faire un update général, pour éviter cela et se prémunir de conflits potentiels on va pouvoir préfixer avec HOMEBREW_NO_AUTO_UPDATE=1.
HOMEBREW_NO_AUTO_UPDATE=1 brew install pdftk-java→ Mettre pdf-forms dans le Gemfile et bundle install
2) Configuration à mettre en place
À mettre dans application.rb 👇

Se créer un petit poro dans le dossier qui vous arrange à l'interieur de app/ pour qu'il soit autoloadé.

3) Comprendre comment assigner les variables sur le PDF
Maintenant qu'on a fait la mise en place et qu'on a un PDF vide, comment va-t-on pouvoir dire qu'on veut telle donnée à tel endroit ?
Tout se passe dans la configuration du PDF, et plus précisément dans la partie "Préparer un formulaire" sur Adobe Acrobat (ou bien sejda, voir fin de l'article).
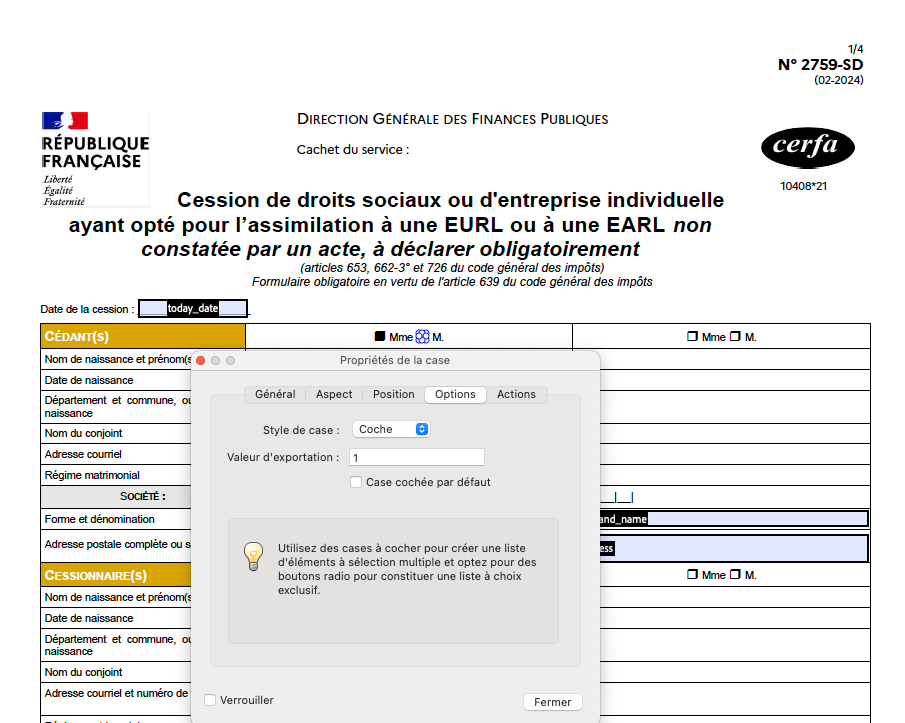
Une fois que vous avez créé votre champ, accédez aux "propriétés" de ce dernier :

→ Pour les champs string pas trop de soucis de ce côté là, vous pouvez les appeler comme vous voulez. Par exemple profile_type, civility, toto, etc. Attention tout de même à ne pas avoir de doublon.

→ En revanche pour les checkboxes soyez attentifs. Même si l'on peut également les appeler comme on le souhaite, first_checkbox par exemple, vous allez devoir renseigner une "valeur d'exportation". Cette dernière déterminera si la checkbox est cochée ou non. Dans l'exemple suivant, j'ai choisi 1. En d'autres termes, une autre valeur que 1 n'aura aucun effet.
4) Création d'un dictionary pour assigner les variables
Maintenant qu'on a configuré les champs dans le PDF il va falloir les remplir, et pour cela on va se créer un dictionary nous permettre d'extraire la logique de mise en forme des données dans un objet dont c'est la seule responsabilité et qui sera très facilement testable. Celui-ci va nous renvoyer un hash que l'on pourra utiliser pour la génération du document.
Si l'on reprend les champs précédemment cités cela donnera :

Maintenant si l'on est pas certain du nom des champs ou bien que l'on souhaite vérifier leurs noms dans notre document, nous pouvons exécuter les commandes suivantes :
pdftk = PdfForms.new
pdftk.get_field_names(mon_document.download)Ce qui va nous retourner un array avec le nom des champs présents dans le PDF :
["profile_type",
"civility",
"toto",
"first_checkbox"]Pratique pour éviter les confusions !
5) Génération du PDF
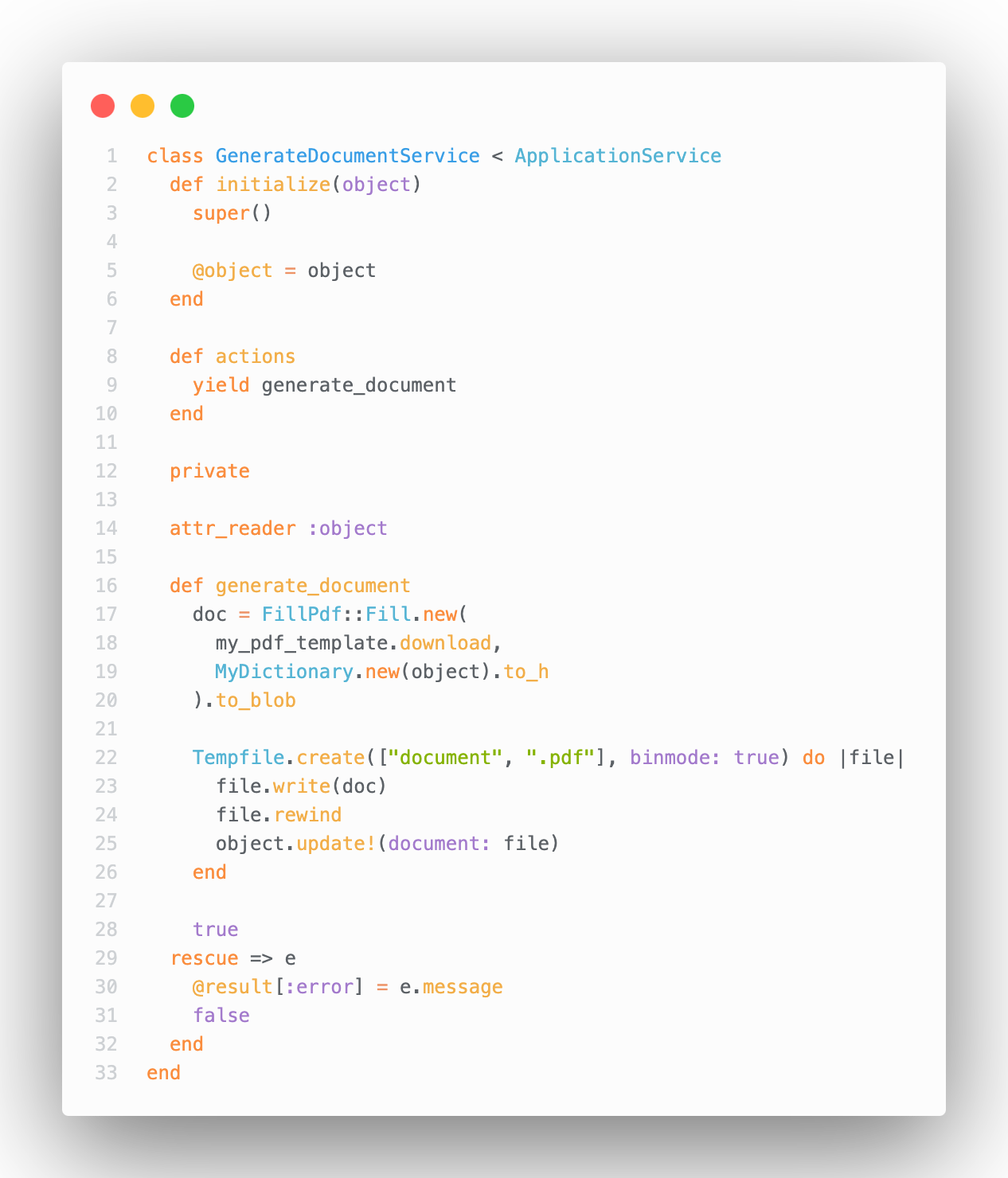
Tout est en place, il ne reste plus qu'à générer notre document et l'enregistrer en db. Vous pouvez vous créer un service comme suit :
Plus que le fichier de test :

NB : La version originale de pdftk est obsolète sur Linux en raison de sa dépendance à GCJ et a été retirée de plusieurs dépôts. En alternative, pdftk-java, une réécriture en Java, est activement maintenu et compatible avec les distributions modernes.
Tada 🚀
Quelques resources :
La gem pdf-forms où l'on peut trouver quelques calls à faire à
pdftkSejda pour créer/nommer des champs et se passer de Adobe Acrobat
— Stanislas
Excellente NL, comme d'habitude... =)