
🍪🆔 Pourquoi et comment on est passé aux UUID v7 dans nos apps Rails
Temps de lecture : 5 minutes
Hello les petits Biscuits !
Bienvenue sur la 43ème édition de Ruby Biscuit.
Vous êtes maintenant 608 abonnés 🥳
Bonne lecture.
Vous lisez Ruby Biscuit, la newsletter Rails de Capsens. S'abonner gratuitement
Considérez le contrôleur suivant :
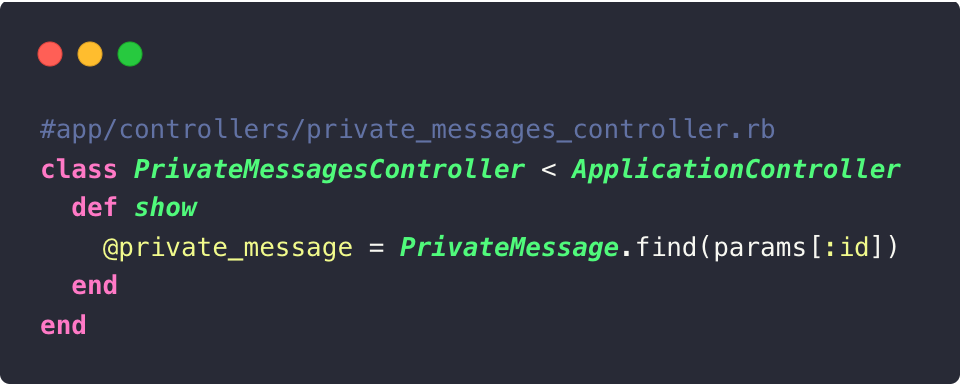
Il présente une faille de sécurité évidente : tout utilisateur de la plateforme peut trouver des messages privés qui ne lui sont pas destinés.
Considérez également cette URL :
/investments/38Il expose une information sensible : un aperçu du nombre d’investissements, surtout si
l’utilisateur vient de créer le sien et a été dirigé vers InvestmentsController#show.
En ce qui concerne le premier exemple, je doute que vous écriviez du code créant une
telle faille de sécurité. Vous avez pris le réflexe d’écrire :
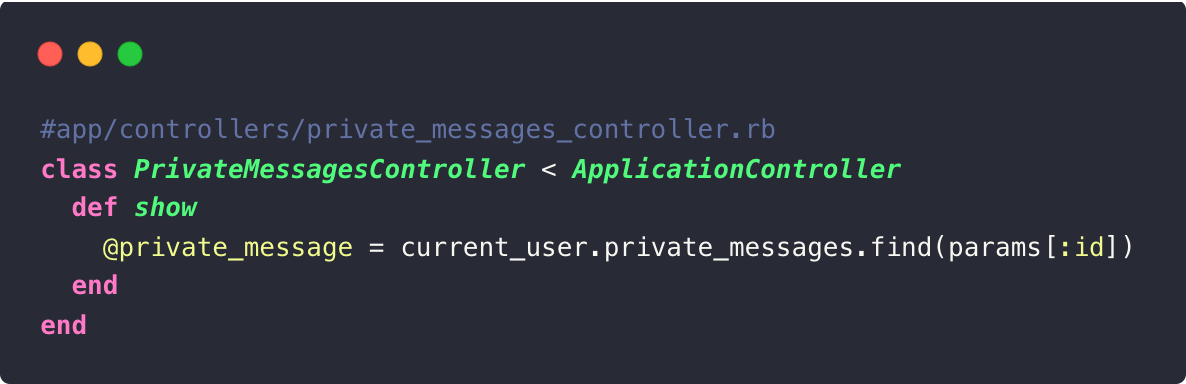
Nous ne maîtrisons cependant pas tout le legacy code d’une application, et ce genre de faille peut exister à notre insu et de façon moins évidente que dans l’exemple.
Quant au second exemple, il n’existe pas de modification facile à appliquer au contrôleur pour ne pas exposer l’identifiant séquentiel de l’investissement.
Les UUID peuvent résoudre ces deux problèmes en même temps. Voyons comment !
Que sont les UUID ?
UUID signifie universally unique identifiers. Les identifiants séquentiels traditionnels se
répètent d’une table de la base de données à une autre, ainsi que d’une application à une autre. Il y a un User avec l’identifiant 1 et un PrivateMessage avec l’identifiant 1. Les mêmes chiffres entiers qui augmentent un à un sont utilisés dans beaucoup d’applications. Au contraire, les UUID sont des identifiants uniques, non seulement d’une table de base de données à une autre, mais d’une application à une autre. Chacun représente un string entièrement unique, qui ne sera jamais répété.
Il y a plusieurs standards d’UUID, mais concentrons-nous sur celui établi par l’Internet
Engineering Task Force. Ce standard comporte neuf versions, qui utilisent plusieurs stratégies pour produire un string hexadécimal de 32 caractères universellement unique.
Quelles sont ces stratégies ?
I. Utiliser des combinaisons de namespaces hashés et uniques
II. Utiliser des timestamps allant parfois jusqu’aux 100 nanosecondes
III. Utiliser des caractères aléatoires
IV. Utiliser une combinaison de timestamps et de caractères aléatoires
En voici un exemple :
019bff1a-a80f-7bad-b4da-ea545f04972cqui met en œuvre cette dernière stratégie.
Des neuf versions d’UUID, PostgreSQL n’en utilise que deux : les versions 4 et 7. La
version 4 des UUID est un string aléatoire disponible depuis la version 13 de PostgreSQL. La version 7 des UUID, qui combine un timestamp et des caractères aléatoires est disponible depuis la version 18 de PostgreSQL.
Le timestamp de la version 7 permet d’ordonner les objets par leur UUID, ce qui n’est
pas possible avec le string aléatoire de la version 4. C’est pour cette raison que la version 7 est préférable à la version 4 pour nos usages.
L’anatomie d’UUID version 7
Intéressons-nous de plus près à la version 7 des UUID. Notre UUID d’exemple comporte 32 caractères hexadécimaux, hors tirets :
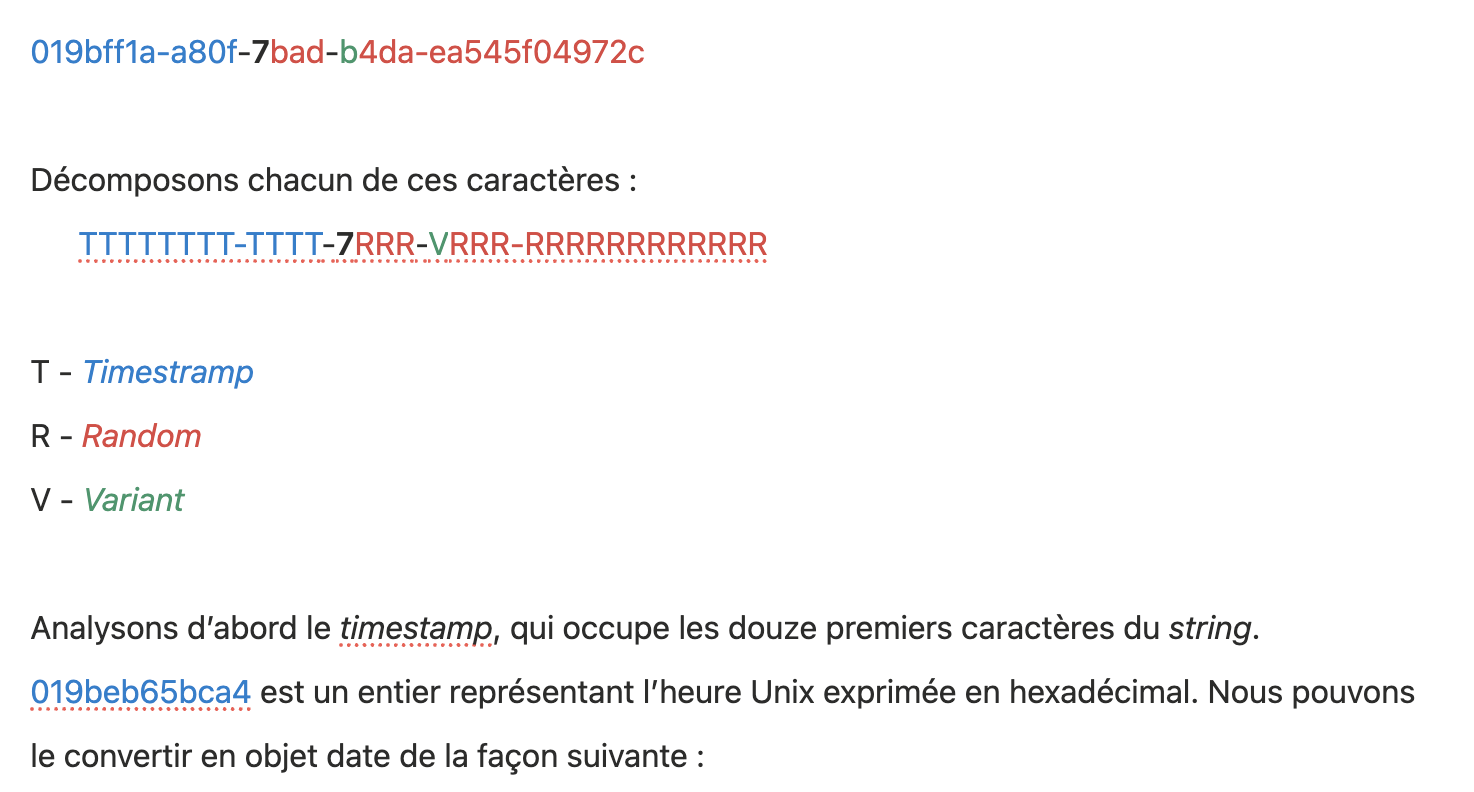

to_i(16) convertit l’hexadécimal en nombre de millisecondes, que nous convertissons ensuite en secondes.
Après le timestamp, il y a un 7, qui est invariable et représente la version d’UUID. S’il
s’agissait d’un UUID version 4, il y aurait un 4.
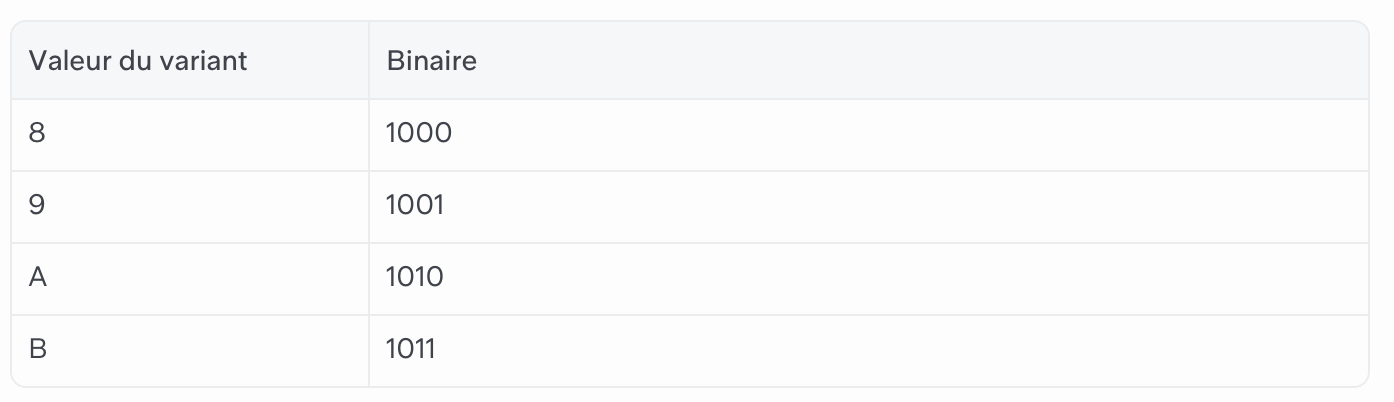
Les autres valeurs sont aléatoires, à l’exception du V, qui représente le variant de l’UUID.
Ce variant permet de distinguer le standard des UUID de l’Internet Engineering Task Force des autres standards. L’Internet Engineering Task Force utilise quatre valeurs pour représenter ce variant : 8, 9, A et B, puisque ces valeurs, exprimées en binaire, commencent toujours par 10.
Dans notre exemple, il s’agit d’un B :
019bff1a-a80f-7bad-B4da-ea545f04972cCela nous laisse 18 caractères hexadécimaux aléatoires. Sans même prendre en compte le timestamp, la probabilité de trouver ces 18 caractères et le variant est 16 caractères hexadécimaux puissance 18 fois 4 variants.
Ce nombre de possibilités colossal rend l’UUID unique, impossible à deviner et donc
sécurisé.
Comment utiliser les UUID avec une base de données PostgreSQL ?
Maintenant que vous avez une compréhension théorique des UUID, regardons comment les utiliser dans une application Ruby on Rails avec PostgreSQL.
Les UUID en PostgreSQL sont des types de colonnes uuid, tout comme les identifiants
séquentiels ont le type bigint.
Même si nous avons une préférence pour le version 7 des UUID, regardons l’implémentation de ces deux versions.
Pour créer une nouvelle table avec un UUID v4, il suffit de faire :

Avec un UUID v7

Les clefs étrangères de l’une et de l’autre version doivent préciser le type uuid :

Revenons à nos exemples initiaux :
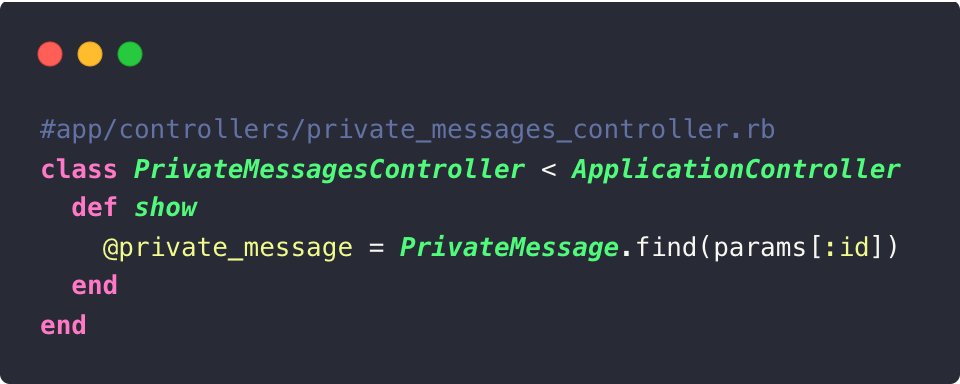
Même si l’on peut accéder à n’importe quel message privé en tapant l’identifiant du
message dans l’URL, il est impossible qu’un utilisateur malveillant puisse deviner l’identifiant d’un message privé qu’il n’est pas censé voir.
Considérez encore notre URL :
/investments/38Avec un UUID, il devient
/investments/019bff1a-a80f-7bad-b4da-ea545f04972cet le nombre d’investissements est désormais caché.
Ainsi, les UUID, qu’ils soient de la version 4 ou de la version 7, sécurisent votre
application depuis la base de données et obscurcissent des informations potentiellement sensibles.
— Andrew, développeur chez Capsens
Merci pour l'article ! J'ai une question concernant l'implémentation des deux versions, c'est exactement le même code, est-ce que je loupe quelque chose ?