
🍪👯 10 000 inscriptions en 15 minutes : comment on a évité de faire planter notre CRM
Temps de lecture : 5 minutes
Hello les petits Biscuits !
Bienvenue sur la 35ème édition de Ruby Biscuit.
Vous êtes maintenant 593 abonnés 🥳
Maintenant Ruby biscuit, c’est aussi votre meilleur allié pour recruter des devs Ruby !
Si vous n’avez pas encore rejoint le club, RDV sur https://recrutement.rubybiscuit.fr
Bonne lecture !
Chez Capsens, nous sommes régulièrement amené à synchroniser des CRM : Hubspot, Salesforce, PipeDrive, Zoho, Brevo, Airtable, etc.
Tous ces CRM implémentent un système de rate limit pour protéger leur infrastructure d'un trop grand nombre de requêtes. Souvent ce dernier se situe aux alentours de 10 requêtes par seconde (Brevo, Hubspot, Airtable).
Lorsqu'il est nécessaire que la synchronisation soit faite en se basant sur des événements, il faut penser à gérer le rate limit pour s'assurer de ne pas le dépasser même en cas de pic de charge.
No no José ! rescue l'erreur 429 ("Too Many Requests") et retry plus tard n'est pas une solution suffisante.
Création du job
Dans la mesure du possible, nous essayons de toujours prioriser l'utilisation de Sidekiq lorsqu'il s'agit d'une API. Pour cet article, nous allons prendre l'exemple d'un CRM quelconque avec lequel nous avons besoin de synchroniser les utilisateurs. La synchronisation devra se faire suite à des événements particuliers :
inscription
investissement signé
investissement payé
investissement annulé
...
Nous allons donc créer un job Sidekiq idempotent qui prendra en paramètre l'ID de l'un de nos utilisateurs en base de données et s'occupera de mettre à jour le contact dans le CRM s'il existe ou de le créer si ce n'est pas le cas avec une liste de champs définie que nous appellerons "dictionnaire".
Afin d'économiser des requêtes au CRM, nous allons implémenter une sorte de clé d'idempotence qui va nous permettre de ne pas effectuer de requête de MAJ ou création du contact au CRM dans le cas où les informations que nous avons envoyé la dernière fois sont identiques. Nous pourrions nous baser sur le timestamp de la resource à synchroniser mais bien souvent les informations à envoyer proviennent de mutliples tables en BDD et la gestion deviendrait bien trop complexe (même en utilisant des touch).
Dans ce contexte, il est donc plus simple et fiable de générer le dictionnaire et créer une signature unique à partir de celui-ci : un digest avec la méthode .hexdigest fournie par Digest::SHA256 et de stocker celle-ci sur l'utilisateur en cas de synchronisation afin de pouvoir la comparer lors du prochain passage.
En informatique, une fonction de hashage ou digest est un résumé court et unique d’un ensemble de données, obtenu en appliquant une fonction de hachage (hash). Il sert souvent à vérifier l’intégrité ou l’authenticité des données, car toute modification du contenu d’origine modifie aussi le digest.
Voici un exemple concret :

Commençons par créer notre Service qui va encapsuler la logique :

Pour le besoin de l'article, nous avons créer un PORO (Pure Old Ruby Object) très simple afin de ne pas avoir de dépendances à des libs mais chez Capsens nous utilisons normalement des DryMonads.
Créons le fichier de tests associé :

Il ne reste plus qu'à créer notre worker Sidekiq qui va appeler notre monad :

et la suite de tests associée :

Cependant la situation actuelle pose un problème, imaginons que la plateforme subisse un pic de traffic accru dû à un passage télévision, nous avons un évènement (entre autres) déclenché par l'inscription d'un utilisateur. Si nous avons 10 000 utilisateur qui s'inscrivent sur une période de 15 minutes, cela ferait donc une moyenne de 11 inscrits par seconde, nous dépasserions le rate limit de notre CRM.
Utilisation de Sidekiq Throttled
Dans ce genre de cas où l'on souhaite limiter la fréquence ou la concurrence d'une tâche au cours du temps, Sidekiq Throttled est généralement notre ami chez Capsens.
C'est une gem Ruby qui ajoute des mécanismes de throttling (limitation) pour Sidekiq, permettant de contrôler simultanément la concurrence des jobs et leur fréquence d’exécution (rate‑limiting).
Elle fournit une configuration simple via sidekiq_throttle, avec des stratégies telles que concurrency (nombre max de jobs concurrents) et threshold (nombre max de jobs dans une période donnée.
Cette dernière est assez simple à configurer, il faut bien sûr ajouter la gem dans le Gemfile puis modifier le fichier de config Sidekiq :
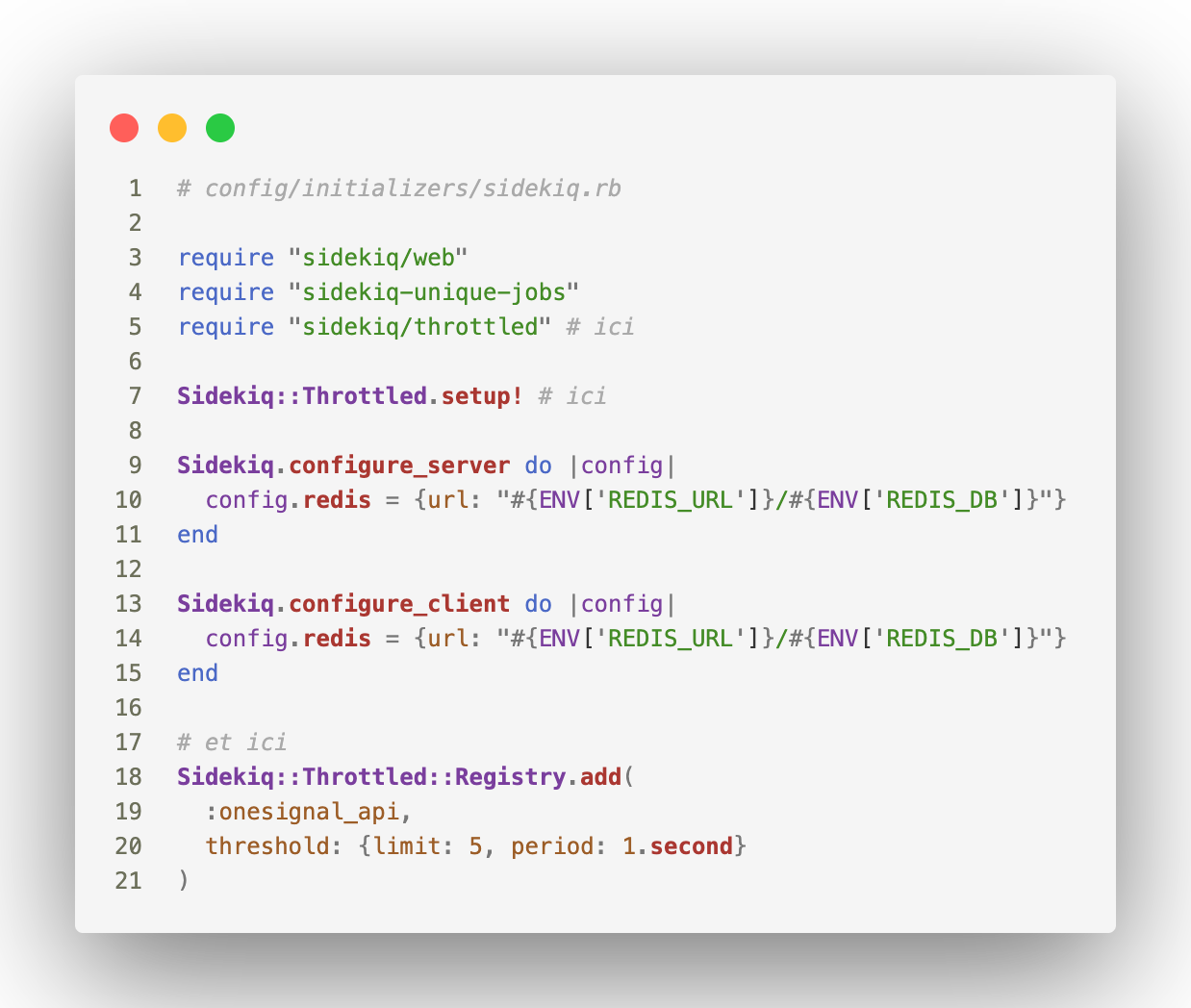
Notez les lignes 18 à 22 où l'on ajoute un Sidekiq::Throttled::Registry , ce dernier nous permet de configurer une limitation pour un ensemble de job plutôt que pour un seul job. C'est très pratique puisqu'il est fort probable que nous implémentions de nouveau job qui vont effectuer des requêtes à notre CRM (supprimer un user, synchroniser d'autres ressources, déclencher des mails). De cette manière, nous nous assurons que tous les jobs qui effectuent des requêtes soient limités de la même manière.
Enfin, notez aussi que même si le rate limit du CRM est de 10 requêtes par seconde, je prend de la marge en limitant à 5 car d'autres parties prenantes effectuent probablement des requêtes au CRM ou parce qu'il est probable que certains de mes futurs jobs effectuent plus d'une requête en s'exécutant.
Maintenant que Sidekiq Throttled est configuré, il ne reste plus qu'à l'implémenter dans notre job :

Désormais vous n'avez plus besoin de vous inquiétez du rate limit, celui-ci est géré à la fois par notre job mais surtout par la limitation fournie par Sidekiq Throttled. Vous pouvez même implémenter une cron pour programmer la synchronisation d'utilisateur en batch sans vous inquiétez de quoi que ce soit. Gardez cependant en tête que cette implémentation permet de préserver le CRM grâce au digest et au throttling mais elle ne préserve pas votre serveur qui lui va travailler dans tous les cas pour générer le digest et le comparer à celui de l'utilisateur afin d'éviter toute requête superflue au CRM.
— Ismaël