
🍪👌 L'API la plus parfaite
🚨 Cette édition est relativement longue, votre boîte mail risque de la tronquer. Je vous conseille de cliquer sur le titre ci-dessus pour l’ouvrir dans votre navigateur web. ☝️
Au programme aujourd’hui :
L'API la plus parfaite par Thomas
L’agence de recrutement pour les leads dévs RoR !
Temps de lecture : 13 minutes
Hello les petits Biscuits !
Bienvenue sur la 16ème édition de Ruby Biscuit.
Vous êtes maintenant 386 abonnés 🥳
Je vous présente Ruby Biscuit sous son vrai visage et bien décoré pour les fêtes !

Voici 2 annonces qui pourraient vous intéresser :
Le Wagon Paris organise un salon du recrutement qui aura lieu la semaine prochaine, le vendredi 15 décembre. Si vous êtes à la recherche de profils tech (dev junior, data et product) pour agrandir vos équipes vous pouvez vous y inscrire ici !
La communauté de Rubyist Toulouse.rb reprend du service ! Si vous êtes de la région n’hésitez pas à aller leur faire coucou le 19 décembre lors de leur prochain meetup
Avant de vous laisser entre les mains de Thomas pour l’article du mois, je tenais à vous rappeler que vous êtes tous les bienvenus pour donner votre avis en commentaire et partager vos expériences sur les sujets que nous abordons. Vous pouvez aussi mettre un petit like ❤️ et/ou partager la newsletter à un copain ou une copine ! 😉
Bonne lecture.
L'API la plus parfaite
Bonjour, fier membre de la communauté Ruby Biscuit ! Il n'est pas rare dans notre profession d'avoir à s'interfacer avec des applications tierces que ce soit pour utiliser des services externes, pour permettre l'accès à nos données, ou tout simplement pour communiquer avec une appli front !
Alors c'est de ça qu'on va parler aujourd'hui : les API ! Et plus précisément, comment faire l’API la plus flexible possible côté client et la plus customisable possible (en terme de droits d'accès), tout en gardant un code clair et maintenable. En tout cas c'est ce qu'on va essayer de faire aujourd'hui 😊 !
Json:api.org
Pour le côté "flexible" de notre API, on va s'appuyer sur la norme jsonapi.org. C'est une norme relativement populaire incluant beaucoup de mécaniques qui, si on les implémente, vont rendre notre API "top tier".
L'autre avantage de suivre cette norme, c'est qu'on va pouvoir s'appuyer sur des outils déjà créés par la communauté ! Alors il est temps d'installer des gems, ou plutôt une gem : jsonapi.rb.
Cette gem va nous faciliter la vie comme c'est pas permis :
Elle nous ajoute la sérialisation dans le format jsonapi.org (via une gem dépendante, jsonapi-serializer)
La désérialisation (pratique quand on s'attaquera aux
createetupdate)Elle ajoute les inclusions
Les sparse fields
La recherche et l'ordonnancement (via une gem dépendante, ransack)
Et en plus de ça la pagination et même le support des erreurs !
Franchement, cette gem (et ses dépendances), chapeau, merci, gracias, thank you, terima kasih, arigatō, y tutti quanti !
Installation
L'installation de la gem est simple, on l'ajoute au Gemfile et on écrit JSONAPI::Rails.install! dans un initializer.
Pour le reste, on va créer trois modèles histoire de pouvoir vous faire une démonstration. Dans l'idée on dit qu'on est un site marchand et qu'on vend des livres de plusieurs éditeurs.
rails g model Publisher name:string client_id:stringrails g model Author name:string description:textrails g model Book publisher:references author:references name:string price:integer
Voici le fichier de seed :

db/seeds.rbAct As JSONAPI
Avant de se lancer à corps perdu dans le développement de nos controllers, on va structurer notre code et on va mettre toute la logique générique de notre API dans une DSL qu'on va appeler ActAsJSONAPI (et oui, pensez à mettre API et JSONAPI dans vos inflections).
Alors voilà à quoi ça ressemble (Pssss, si tu es dans ton navigateur, tu veux agrandir les images avec les petites flèches en haut à droite) :

Sur le hook d'inclusion :

Puis les, ou plutôt “la”, méthode de singleton qui nous permet de définir notre DSL :

Et maintenant les méthodes d'instance :

Bon, c'était déjà un gros morceau mais on a pas fini. D'abord je vous montre les modules custom qu'on include au tout début de la DSL.
On un module pour la gestion des erreurs :

Je ne vous tiens pas la main pour celui-là, il s'occupe de la gestion et du formatage des erreurs, et si vous n'êtes pas en environnement de production, il vous rajoute même la backtrace (parce que quand on rescue, on perd la backtrace dans les logs vu que le serveur ne fait plus une 500)
Et le suivant, c'est un module pour gérer les autorisations :

app/controllers/concerns/api/v1/act_as_jsonapi/authorization.rbPour l'instant, il nous sert juste à vérifier que notre controller effectue bien la mécanique d'autorisation sur les filtres permis. C'est pas grand chose pour le moment mais encore une fois, on l'étoffera quand on étoffera notre mécanique d'autorisations.
Et enfin, les actions par défaut qui sont ajoutées optionnellement en fonction de la configuration de la DSL :

On fait pareil pour le show :

app/controllers/concerns/api/v1/act_as_jsonapi/default_show.rbEt pour le destroy :

app/controllers/concerns/api/v1/act_as_jsonapi/default_destroy.rbEt on va s'arrêter là. On ne verra pas les actions de create et d'update tout de suite, il nous faudra mettre en place d'autres gros blocs de code avant ça alors faisons déjà fonctionner ce qu’on a. Ça serait bien !
MVC
Okay ! Maintenant qu'on a setup la base de notre super API, il est temps de voir ce que ça vaut. Alors on va très rapidement créer les controllers et serializers qu'il nous faut.
Pour le controller, c'est assez simple, on déclare la constante, on y met notre DSL et le tour est joué :

app/controllers/api/v1/api_controller.rbBon, je vous ai mis que le controller pour Book mais imaginez que je fais la même chose pour les Publisher et Author (et si vous ne savez plus de quoi on parle, retournez au début de l'article ^^)
De la même façon on ajoute les serializers, même topo je vous montre que celui des Book :

Et enfin faut ajouter les routes m'enfin vous êtes suffisament balèzes pour faire sans mon aide !
Démo
Et ça y est ! On y est enfin ! La démo ! On va pouvoir voir cette magie que je vous promets depuis le début. Alors, est-ce que ça valait vraiment toute cette peine ?
On va commencer petit avec
http://localhost:3000/api/v1/books
Whaowwwwww ... www ... Bon, en vrai j'ai plus à vous montrer mais déjà je veux vous familliariser avec la structure de la spec jsonapi.org.
Vous pouvez remarquer que les données "principales" sont dans une clé data. A l'intérieur, pour chaque élément on a le type, l'id, sympa, puis les attributes et les relationships.
Les attributes c'est exactement ce qu'on imagine. Par contre les relationships sont plus intéressantes puisqu'elles ne contiennent, pour chaque association que vous avez mises dans votre serializer, uniquement le type et l'id de ou des objets associés. Gardez ça dans un coin de votre esprit on va y revenir. Et puis vous avez la clé links qui donne le lien vers ce record en particulier.
Outre la clé data, on a une clé meta (vous vous souvenez qu'on avait fait une méthode pour pouvoir personnaliser cette clé ?) et une clé links plutôt intéressante puisqu'elle contient les infos de navigation liés à la pagination !
Sauf que là, la pagination c'est rigolo mais on a 4 records alors que la taille par page est à 30 par défaut (ça vient de la gem). Pas d'inquiétude, on peut changer ça avec le params page, par exemple
http://localhost:3000/api/v1/books?page[size]=2&page[number]=2
Okay, là c'est déjà plus sympa. Un lien vers la page précédente et vers la première page. Et si on était pas sur la dernière page on aurait aussi un lien vers la page suivante et vers la dernière page.
Mais attendez, y'a pas que la pagination ! Je vous avais dit de mettre les relationships dans un coin de votre tête. Bon et bien si vous l'aviez fait tant mieux parce que tout de suite je vous montre les inclusions, avec ça
http://localhost:3000/api/v1/books?include=publisher
ARRÊTE ! Arrête ! Annule tout !
On a un problème et pas des moindres, les plus perspicaces d'entre vous l'auront évidemment vu mais on a une N+1 sur les bras (pour ceux qui ignorent ce qu'est une N+1, c'est un terme qui vient des mesures de complexité d'algorithmes et il faudrait demander à un scientifique de l'informatique plus de précisions mais dans le contexte ça veut dire qu'on fait beaucoup plus de requêtes SQL que ce qu'on devrait faire) !
Heureusement, le correctif n'est pas bien compliqué, il suffit d'includes dans notre requête les mêmes choses que ce qui est demandé dans l'url.
On ajoute une petite méthode ici :

app/controllers/concerns/api/v1/act_as_jsonapi.rbUne autre par là :

app/controllers/concerns/api/v1/act_as_jsonapi/default_index.rbEt on override les serializers pour lazy_load dans le cas où le include n'est PAS demandé :

app/serializers/api/v1/application_serializer.rbMaintenant, on peut repartir
http://localhost:3000/api/v1/books?include=publisher
C'est beaucoup mieux, et la réponse ?

Le premier changement comparé à tout à l’heure, c'est dans les relationships, on voit que l’association author n'est pas chargée (par contre elle apparaît pour que le client comprenne qu'elle existe).
Ensuite, on voit qu'à la racine en plus de la clé data, il y a une clé included qui contient des objets aussi. Ce sont tous les objets qu'on a inclus au travers des associations !
(Une brève mise en garde cependant, le included n'est pas paginé, ce qui rends particulièrement dangereux le fait d'exposer des relations has_many dans votre API. Mon conseil c'est de n'exposer que les associations belongs_to.)
Non mais n'empêche ! Une API qui vous permet de récupérer les associations en une seule requête ! Et sans N+1, même en GraphQL ça aurait été galère à faire ! Et c'est pas tout !
Les "sparse fields" ça vous parle ? Comme en GraphQL encore une fois c'est la capacité à sélectionner les champs que vous voulez dans votre retour, par exemple
http://localhost:3000/api/v1/books?fields[book]=name
Et hop, pas d'infos en trop, juste pile-poil ce qu'il vous faut ! Mais vous en voulez
plus ? La possibilité d'ordonner les résultats peut-être ? C'est parti
http://localhost:3000/api/v1/books?sort=price
Pas totalement impressionné ? Et si on trie par prix décroissant, puis par nom par ordre alphabétique si c'est le même prix ?
http://localhost:3000/api/v1/books?sort=-price,name
C'est pas mal hein ? Ho et je ne vous ai pas encore parlé de la recherche ! Dites ce que vous voulez et je vous le trouve ! Tous les livres avec un prix strictement inférieur à 12€ ? Tout de suite
http://localhost:3000/api/v1/books?filter[price_lt]=1200
Ou alors, vous faites un champ de recherche et vous voulez chercher aussi bien dans le titre des livres que dans le nom des éditeurs, ça marche aussi !
Avec "Gaston" comme valeur pour la recherche
http://localhost:3000/api/v1/books?filter[name_or_publisher_name_cont]=Gaston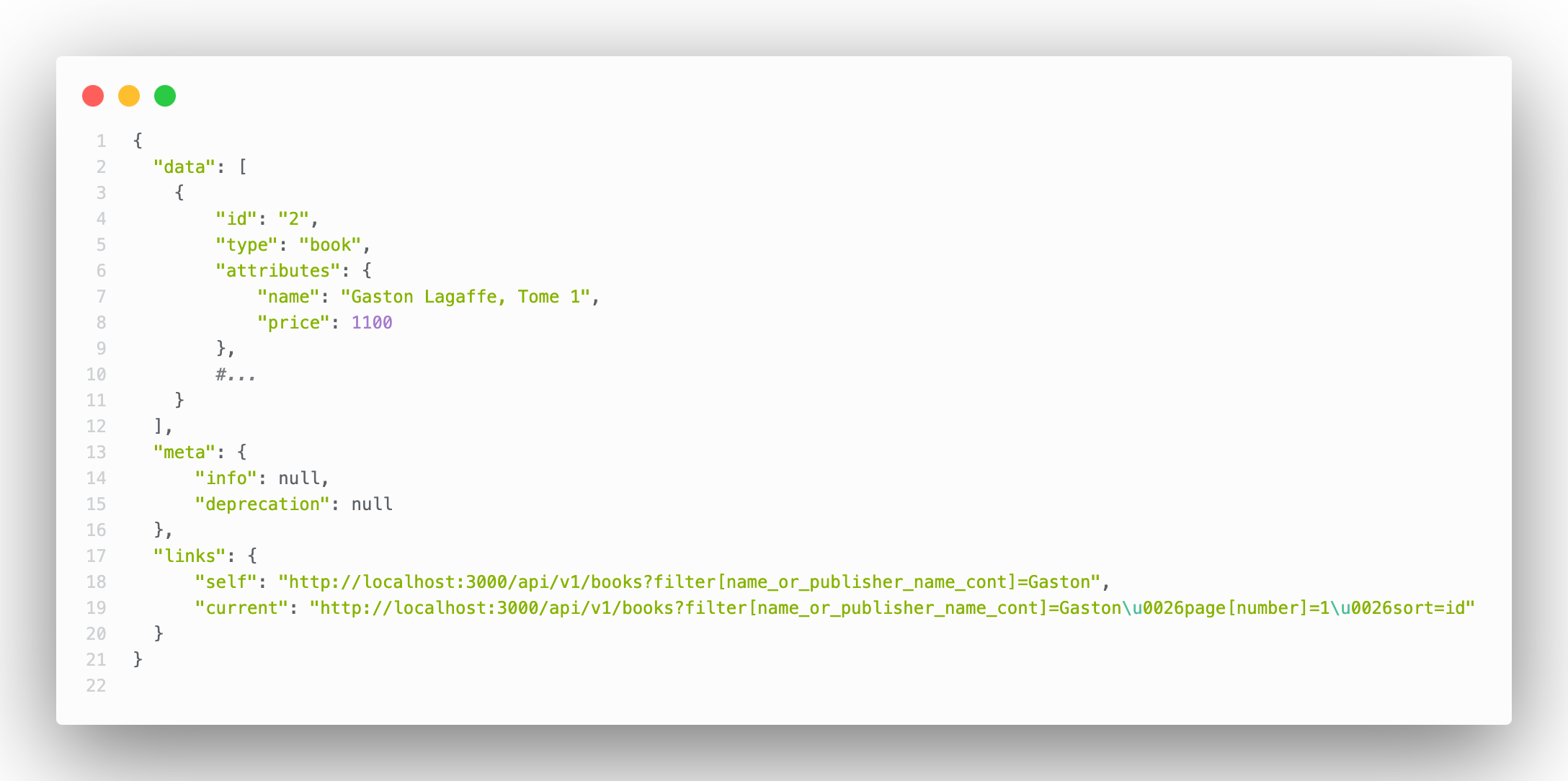
Et la même requête avec "Dupuis" comme valeur
http://localhost:3000/api/v1/books?filter[name_or_publisher_name_cont]=Dupuis
C'est pas incroyable ça ! Toute la recherche sur tous vos champs de base de donnée sans avoir aucun code custom à écrire. C'est plus une API c'est un ORM le truc !
Niveau supérieur 🚀
Pour finir avec la démo, j'ai envie de vous montrer deux exemples de ce qu'on peut faire en combinant les fonctionnalités de notre API.
Imaginons qu'on veuille afficher le prix du livre le plus cher pour un éditeur donné, on pourrait faire :
http://localhost:3000/api/v1/books?filter[publisher_client_id_eq]=dupuis&sort=-price&page[size]=1&fields[book]=price
Avec le sparse field on récupère uniquement le prix, puisque c'est ça qui nous intéresse. Avec la pagination on ne récupère qu'un seul élément et avec le tri on récupère celui avec le plus grand prix. Et avec les filtres de recherche, on ne prend que les records associés à l'éditeur "Dupuis".
Essayez de faire ça avec n'importe quel autre style d'API, ça risque d'être un peu plus galère vous ne pensez pas ?
Autre exemple, on a une page avec un champ de recherche par auteur et quand on valide la recherche on veut afficher tous les éditeurs chez qui cet auteur a publié un livre, avec la liste de tous les livres de cet éditeur et le nom de l'auteur pour chaque livre. Ça donne quelque chose comme
http://localhost:3000/api/v1/publishers?filter[books_author_name_cont]=Bes&include=books,books.author&fields[publisher]=name,books&fields[book]=name,author&fields[author]=name
Ici on utilise les filtres pour restreindre sur le nom de l'auteur en passant par la chaîne d'association books puis author. On inclut également ces deux associations et on utilise les sparse fields sur les trois types de donnée différents pour ne sélectionner que ce qu'on veut.
Alors oui, je sais que c'est bizarre d'afficher tous les livres de l'éditeur et pas juste ceux qui ont été publiés par l'auteur de la recherche. J'ai pris cet exemple pour vous montrer qu'on pouvait inclure des associations en chaîne mais si on voulait faire quelque chose de plus logique on aurait pu faire
http://localhost:3000/api/v1/books?filter[author_name_cont]=fran&include=publisher,author&fields[publisher]=name,books&fields[book]=name,author&fields[author]=name
Et voilà !
Conclusion
Je pense que vous l'avez vu avec les exemples mais on a une API hyper versatile. On a suffisamment de fonctionnalités pour pouvoir l'utiliser selon n'importe quelle stratégie de consommation. Et ça c'est vraiment bien parce que ça veut dire que vous pouvez exposer cette API directement à n'importe quelle équipe front et elle satisfera leurs besoins.
Et l'avantage pour vous, dev back qui développez l'API, c'est que vous pouvez confortablement rester dans le modèle orienté objet / CRUD que Rails vous enjoint fortement à respecter, sans avoir à tordre le framework dans tous les sens.
Sauf qu'il manque encore pas mal de choses. Déjà, dans tout l'article je vous ai dit "mais ça on en reparlera plus tard", parce qu'on s'était fixé à la base d'avoir non seulement une API flexible pour le client, mais aussi customisable en terme d'autorisations et pour l'instant on a pas vraiment vu de système d'autorisations. Et il y a aussi les actions de création et d'édition qui nous restent à voir.
Alors oui, on en reparlera, c'est promis, dans la prochaine édition de ce Ruby Biscuit.
D'ici là, profitez bien de ce que vous avez, essayez de nous pardonner ce petit suspense.. A dans un mois, on a hâte !
— Thomas
L’agence de recrutement pour les leads dévs RoR !
Comme vous le savez, derrière Ruby Biscuit, il y a Capsens 👋 , nous sommes une agence web qui fait du Ruby on Rails depuis 10 ans.
Avec le temps on s'est rendu compte que beaucoup de dévs choisissent leur entreprise un peu par hasard alors qu'ils pourraient davantage s'épanouir et se valoriser dans des structures qui leur correspondent mieux. De plus on sait à quel point les process de recrutement peuvent ne pas être adaptés à notre métier et nos profils.
Ce qui tombe super bien c'est que chez Capsens nous avons une excellente connaissance de l'écosystème RoR en France, avec un réseau d'entreprises considérable. La plupart étant des boites bien installées (+ de 5 ans), avec des équipes tech déjà présentes et qui recherchent avant tout des leads dévs et dévs séniors.
C'est pourquoi nous avons décidé de mettre à profit nos ressources pour vous aider à trouver le poste de vos rêves !
Alors tu as plusieurs années d’expériences ? Tu souhaites trouver le prochain poste de lead dév de tes rêves ?
Concrètement voilà ce qui va se passer :
Réponds à cette newsletter en te présentant en deux lignes !
Je t’envoie aussitôt notre test technique pour évaluer ta séniorité
Je te propose des créneaux pour un appel afin de faire ta connaissance et que tu me dises ce que tu cherches pour t’épanouir dans une entreprise.
Je te propose 3 entreprises qui correspondent à ton profil et tes aspirations. Pour chacune de ces entreprises :
Je me charge de te donner un max d’infos et répondre à toutes tes questions par message (horaires, ambiance, taille et séniorité de l’équipe, responsabilités, marge de manœuvre pour la négociation du salaire, localisation des bureaux, politique de télétravail, etc). Pas d’appels inutiles.
Avant de rencontrer le recruteur lui-même, je te mets en relation avec un développeur de leur équipe. Tu pourras alors te faire une idée de comment ça se passe de l’intérieur.
Enfin, le recruteur te recevra ! Il aura déjà eu toutes les informations que je lui aurai transmises sur toi ce qui vous permettra d’aller à l’essentiel !
Lance-toi, on attend ton e-mail ! Et si tu aimes déjà ton travail, ne nous contacte surtout pas ! Ou alors fais-le pour nous recommander ta boîte 😉
Thomas & Mélanie
Très intéressant et utile ! Comme nombreux de vos articles !
Mais pour être encore plus utile, il faudrait être capable de copier/coller votre code ... Imaginez une seed, ou un controller à recopier ?! (Bon sans Copilot evidemment ... ^^)
Article sur l'Api très intéressant. Je veux bien le test par curiosité.