


[HORS SÉRIE #2] LLM et Ruby : Naviguer dans la Révolution du Développement Logiciel
Nous plongeons dans l'évolution des LLM pour doter les développeurs Ruby des connaissances essentielles à cette nouvelle ère informatique.
Hello les petits Biscuits !
Bienvenue sur la 2ème édition hors série de Ruby Biscuit dédiée à l’IA.
Vous êtes maintenant 391 abonnés 🥳

Cette édition spéciale pourrait plaire à d’autres, aidez-nous à la faire connaître en la partageant à vos ami(e)s dévs ! Un petit pas pour l’homme, un grand pas pour Ruby Biscuit ❤️
Temps de lecture : 5 min
Après notre plongée passionnante dans le monde de l'IA et Ruby (voir notre édition précédente ici), où nous avons dévoilé le potentiel du pré-entraînement et de la modélisation du langage, nous allons aujourd'hui élargir nos horizons. Nous approfondissons cette fusion entre l'IA et la programmation, incarnée par les Modèles de Langage de Grande Échelle (🇬🇧Large Language Model - LLM) qui redessinent le paysage du développement logiciel et interpellent sur le futur rôle des développeurs.
Ces prodiges de l'IA, nés du paradigme de pré-entraînement, sont de véritables couteaux suisses dans l'univers des données massives. Une nouvelle classe de modèles connue sous le nom de Modèles Fondation Pré-entraînés (🇬🇧 Pre-trained Foundation Models) a émergé comme un composant clé et polyvalent de l'intelligence artificielle à l'ère des grandes données. Actuellement, le terme de modèle fondation est souvent utilisé de manière interchangeable avec celui de LLM, bien qu'il y ait une distinction subtile entre les deux. Si les LLM jonglent avec les mots, les modèles fondation jouent sur un terrain plus vaste, celui des fonctionnalités systémiques.
Qui mieux que OpenAI pour illustrer cette révolution ? En lançant le modèle Transformateur Pré-entraîné Génératif (GPT) en 2018 et ses versions ultérieures (GPT-2, GPT-3, GPT-3.5, et GPT-4), OpenAI a non seulement repoussé les limites de la performance générative, mais a aussi captivé l'intérêt du public, pour ChatGPT en particulier, et pour les Modèle de Langage à Grande Échelle de manière plus générale. Côté monde de programmation, OpenAI a introduit en 2021 CodeX, un descendant de GPT-3 spécialement affiné pour le code. Copilot de GitHub, qui a été alimenté par CodeX et maintenant GPT-4 pour sa nouvelle version, n'est pas juste un outil, c'est l’un de nos compagnons modernes de développement Ruby.

Avant de nous aventurer plus loin, prenons un moment pour comprendre leur essence : ces LLM sont en fait des réseaux de neurones avancés. Ces réseaux, inspirés par les réseaux neuronaux humains, sont des assemblages de nœuds ou "neurones" artificiels interconnectés et disposés en couches. Imaginez un vaste réseau de villes (les neurones), chacune connectée par des autoroutes d'informations, apprenant et s'adaptant comme une communauté vivante. Dans le cas des LLM, ces réseaux de neurones sont entraînés pour comprendre et générer le langage, en apprenant des motifs complexes dans d'énormes ensembles de données textuelles.
Cette architecture neuronale a permis aux LLM aujourd’hui de devenir si populaires, grâce à leur polyvalence, efficacité et hautes performances, s'adaptant à diverses tâches sans besoin d'une programmation spécifique. Leur efficience réduit les coûts et accélère le développement de solutions, surpassant les modèles traditionnels pour des tâches complexes. Ces capacités proviennent de leur formation sur d'énormes corpus de données, comme GPT-3, entraîné sur 45 To de données textuelles et équipé de 175 milliards de paramètres.
Mais qu'est-ce qu'un paramètre, demandez-vous ? Imaginez-les comme les rouages internes d'une horloge complexe, chaque paramètre étant un engrenage essentiel. Ils sont ajustés durant l'entraînement pour perfectionner la compréhension et la génération du langage. Chaque paramètre joue un rôle crucial dans la détermination de la réponse du modèle. Pendant la phase d'entraînement, ces paramètres sont méticuleusement ajustés, permettant au modèle de réduire les erreurs et d'affiner ses prédictions. Avec des milliards de paramètres, comme les 175 milliards de GPT-3, les LLM peuvent capter des nuances extrêmement fines dans le langage. Ces paramètres sont la clé de leur capacité à comprendre le contexte, reconnaître les structures linguistiques et produire des réponses cohérentes et pertinentes. Le nombre de paramètres est souvent utilisé comme mesure de la taille d'un LLM.
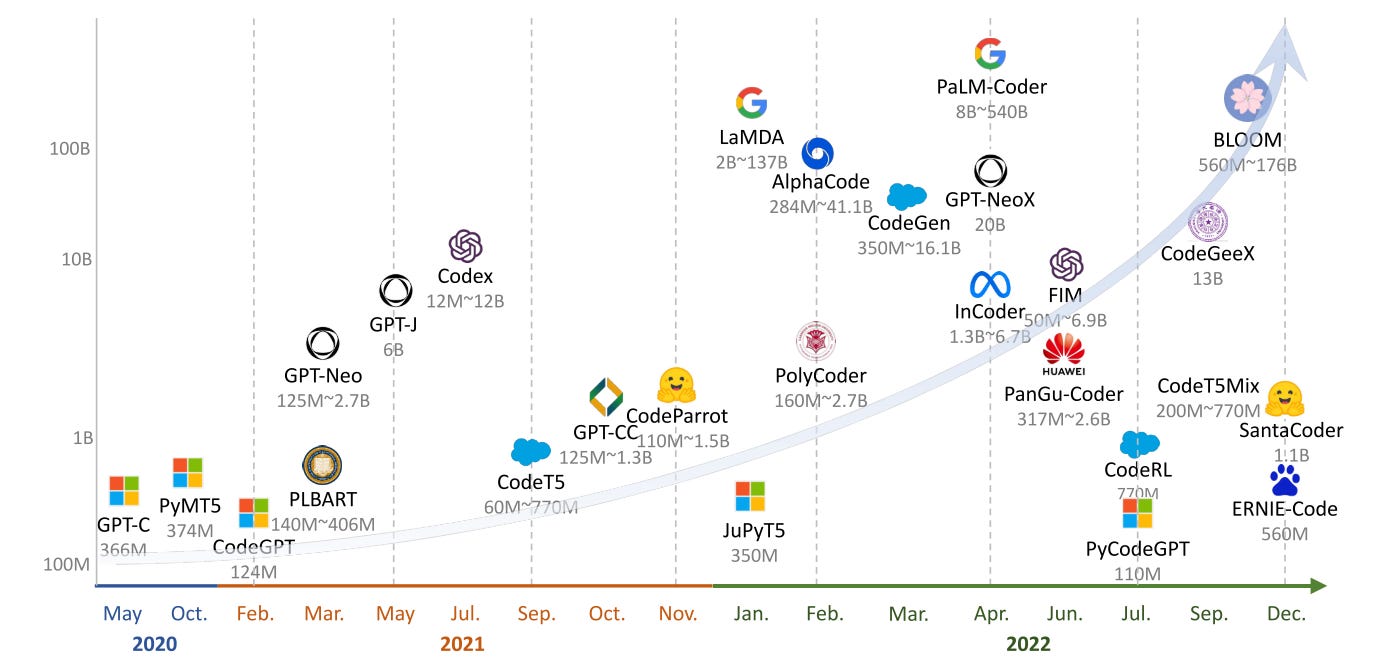
Alors que nombre de ces LLM ont prouvé leur efficacité extraordinaire, en tant que développeurs nous nous heurtons à un aspect plus énigmatique de leur nature. Ces modèles, malgré leur précision et leur finesse linguistique, ne sont pas exempts de défis. De nombreux chercheurs et praticiens ont souligné, à la fois scientifiquement et de manière anecdotique, que l'hallucination est un problème omniprésent pour les LLM [1] qui pose en plus des problèmes spécifiques pour l’ingénierie logiciel [2]. Comme avec l'intelligence humaine, l'hallucination signifie la création de réponses fictives qui semblent cohérentes mais sont fondamentalement erronées. La principale préoccupation dans le contexte du développement Ruby, est que les LLM peuvent introduire des bugs ou générer du code non fonctionnel qui semble correct. Cela peut être particulièrement difficile car l'incorrectitude n'est pas toujours évidente, menant à des erreurs potentielles dans le processus de développement.
Ce risque est exacerbé par la caractéristique fondamentale des LLM de prédiction mot à mot, qui, bien que focalisée sur la cohérence immédiate, peut négliger le contexte global. Ils fonctionnent en analysant le contexte immédiat, c'est-à-dire les mots qui précèdent la position courante dans le texte, et sont optimisés pour prédire le mot suivant qui serait le plus probable ou le plus cohérent dans ce contexte local.

Cependant, cette approche peut être limitée, car elle ne tient pas compte de l'intégralité du contexte ou de l'intention globale du code. En se concentrant uniquement sur le prochain mot le plus probable, les LLM peuvent générer des séquences de code qui, bien que syntaxiquement correctes et logiquement cohérentes à court terme, peuvent conduire à des incohérences ou des erreurs lorsqu'elles sont considérées dans un contexte plus large du projet. Par exemple, un LLM pourrait générer une fonction qui semble résoudre un problème spécifique mais qui en réalité introduit une faille de sécurité ou un comportement imprévu ailleurs dans l'application.
Ainsi, pour les développeurs Ruby, la responsabilité incombe souvent au développeur d'évaluer et de valider de manière critique les sorties des LLM, en s'assurant que le code halluciné ne s'intègre pas dans le produit final. Cela est particulièrement important dans le contexte des tâches de complétion de code, où les LLM agissent comme des systèmes de recommandation. Il est ainsi essentiel que les développeurs ne s'appuient pas uniquement sur les sorties des LLM. Une compréhension humaine approfondie et une vérification rigoureuse sont nécessaires pour assurer que le code généré est non seulement syntaxiquement correct, mais aussi logiquement cohérent et fonctionnellement approprié dans le contexte global du projet.
Toutefois, contrairement à de nombreuses autres applications des LLM, les développeurs ont généralement la chance de disposer d'une vérité de base automatisable (exécution logicielle), contre laquelle la plupart des artefacts générés peuvent être évalués. La communauté de recherche en génie logiciel a déjà consacré beaucoup de temps à produire des techniques automatisées et semi-automatisées pour vérifier les résultats potentiellement incorrects produits par les humains. Cela signifie qu’il existe une grande expérience et expertise qui aident à identifier et à rectifier les sorties hallucinées pour assurer une certaine fiabilité.
Nous allons dédier la prochaine édition au problème de fuite de données, une préoccupation significative pour les industries et les applications où la confidentialité et propriété des données et du code est primordiale. La fuite de données dans le contexte des LLM fait référence à l'exposition ou à l'incorporation involontaire d'informations sensibles ou privées, telles que des clés API, dans les sorties du modèle. Cela peut se produire lorsque les LLM sont entraînés sur des ensembles de données qui incluent des informations confidentielles ou propriétaires, que le modèle pourrait ensuite reproduire dans d'autres contextes, menant à des violations potentielles de la sécurité ou de la confidentialité.
Le sujet des LLM est très vaste, et les ressources dessus sont nombreuses et extensives. On y reviendra souvent dans d’autres éditions futures pour en couvrir d’autres aspects.
Si vous avez des questions d’ici la, n’hésitez pas à me les poser directement à rubybiscuit@capsens.eu. J’y répondrais avec plaisir dans les prochaines éditions hors série. 😊
[1] J. Yang, H. Jin, R. Tang, X. Han, Q. Feng, H. Jiang, B. Yin, and X. Hu, “Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond,” 2023.
[2] W. Ma, S. Liu, W. Wang, Q. Hu, Y. Liu, C. Zhang, L. Nie, and Y. Liu, “The scope of ChatGPT in software engineering: A thorough investigation,” 2023.
— Chyrine