
🍪☠️ PDF et JavaScript malveillant : comment on protège nos plateformes
Temps de lecture : 10 minutes
🚨 Cette édition est relativement longue, votre boîte mail risque de la tronquer. Je vous conseille de cliquer sur le titre ci-dessus pour l’ouvrir dans votre navigateur web. ☝️
Temps de lecture : 10 minutes
Hello les petits Biscuits !
Bienvenue sur la 27ème édition de Ruby Biscuit.
Vous êtes maintenant 540 abonnés 🥳
Maintenant Ruby biscuit, c’est aussi votre meilleur allié pour recruter des devs Ruby !
Si vous n’avez pas encore rejoint le club, RDV sur https://recrutement.rubybiscuit.fr
Bonne lecture.
En finir avec les PDF infectés au js
En mai 2024, une faille majeure a été découverte dans la bibliothèque PDF.js, utilisée par de très nombreux iframes pour permettre la visualisation et la prévisualisation de fichiers PDF dans une page web. Cette faille permettait d'injecter du code javascript dans une FontMatrix qui n'était pas censée en accueillir et ensuite de s'assurer de son exécution lors de l'interprétation du fichier par un lecteur. Ce type de faille est une porte d'entrée pour des attaques de type XSS, bien qu'elle n'en permette pas une seule.
Le cross-site scripting (abrégé XSS) est un type de faille de sécurité des sites web permettant d'injecter du contenu dans une page, provoquant ainsi des actions sur les navigateurs web visitant la page. Il est par exemple possible de voler la session en récupérant les cookies.
Les CVE concernant l'exécution arbitraire de javascript via des fichiers PDF dans des pages web sont nombreuses, et il y a aussi des multitudes de formes d'exécution de javascript volontairement permises par le format PDF. Celles-ci sont généralement bloquées par le navigateur mais il y a des exceptions.
Aujourd'hui nous allons apprendre comment nous en débarrasser. Après avoir lu cet article, vous saurez comment implémenter un sanitizer en ruby qui vous protège durablement de la CVE de mai 2024 et d'autres types d'injections au js. Vous serez également solidement armés pour réagir efficacement et rapidement à la prochaine CVE de ce style et capables de :
Comprendre sur quoi se base la CVE
Adapter votre sanitizer
Créer vos propres fichiers infectés pour le tester
I - Introduction, les actions javascripts et les fontmatrix
Entre la création du format PDF en 1992 où seulement 12 types d'objets étaient autorisés et sa dernière mise à jour en 2009 qui en compte plus de 70, de nombreuses fonctionnalités ont été ajoutées. Et avec elles beaucoup de vulnérabilités.
Une partie non négligeable de ces vulnérabilités et dangers ont été introduits en même temps que les scripts javascript.
La plupart de ces scripts ne seront pas malveillants : widgets, liens dynamiques, actions sympathiques et variées au clic d'un bouton ou dès l'ouverture d'un fichier : le javascript a été admis pour améliorer et enrichir l'expérience utilisateur.
D'autres le seront probablement, c'est le cas des PDF écrits pour contenir du javascript de sorte à exploiter la CVE de mai 2024.
Je vais vous montrer comment écrire un script ruby qui sanitise les fichiers PDF pour leur enlever les éléments javascripts légitimes ou illégitimes.
Mais avant il y a quelques pré-requis nécessaires :
Une compréhension globale du format PDF
Une connaissance des emplacements et des formes que le javascript peut occuper dans un PDF
Des fichiers PDF "infectés" pour tester nos scripts
Nous allons obtenir tout cela en créant ensemble et de toute pièce un fichier PDF infecté au javascript (inoffensif bien sûr) !
II - Créons un fichier corrompu
Nous allons dans cette partie écrire à la main, de A à Z, un fichier PDF. Le javascript pouvant se trouver dans de très nombreuses sections d'un PDF, je montrerai pour chaque section dans un premier temps la version saine et dépourvue de javascript, puis la version infectée.
Cependant, il est impossible de présenter l'ensemble des objets liés à des actions javascript en un seul article tant ceux-ci sont nombreux. La norme PDF 32000-1:2008 ou PDF 1.7 décrit de façon exhaustive ces objets si cela vous intéresse (page 422).
Pour chaque section, les fragments de code PDF en version saine présentés dans l'article, une fois assemblés, formeront un fichier PDF valide et non corrompu.
Si vous souhaitez créer vous même votre PDF infecté, il faudra adapter les offsets de la table des références (je vous expliquerai tout ça en détail le moment venu).
Speedrun
Si vous souhaitez speedrun la lecture de cet article, et n'en sortir qu'un script de sanitisation et des fichiers de payload pour le tester, vous pouvez sauter directement à la partie suivante où vous trouverez les deux.
Je ne vous conseille cependant de ne pas faire cela, l'intérêt de coder votre propre sanitizer étant de pouvoir l'adapter rapidement à toute nouvelle CVE permettant une exécution de javascript dans un pdf via des moyens détournés. Cela peut être plus compliqué sans une vague compréhension du format PDF et des objets javascript.
Le format général
Une façon de se représenter un fichier PDF serait de dire qu'il contient globalement 3 sections :
L'en-tête qui annonce le format et la version (très court)
Le corps qui abrite le contenu (ou charge utile) du PDF
La fin de fichier qui regroupe la table des références, le trailer et le marqueur de fin de fichier : des éléments utiles à la bonne interprétation du document mais n'ajoutant généralement pas de contenu à proprement parler.

Nous allons remplir ce guide progressivement dans cette partie.
En tête
Un PDF commence directement par une section d'en-tête. L'en tête précise le format : PDF, la version : 1.3 et quelques caractères binaires pour annoncer que le fichier sera encodé en binaire.
Le fichier que nous allons écrire étant constitué de très peu d'objets, il sera valide et lisible avec n'importe quelle version et par n'importe quel lecteur PDF (si vous souhaitez écrire la version contenant du JS à la main, utilisez une version récente comme la 1.8 ou au minimum postérieure à 1.2).

Corps
Le corps regroupe tout le contenu d'un PDF : c'est une suite d'objets indirects. Ces objets peuvent être de types variés. Cependant certains types d'objets sont nécessaires à l'élaboration d'un PDF valide minimal.
Afin de comprendre le format du corps, quelques définitions s'imposent à ce sujet.
Le corps d'un fichier PDF est constitué d'une série d'objets indirects.
Les objets indirects sont composés d'un numéro d'objet (un identifiant), d'un numéro de génération (qui commence à 0 et s'incrémente si l'objet est dupliqué).
Puis obj [Contenu objet] endobj
1 0 obj
[CONTENT]
endobjUn objet indirect peut être vu comme un contenant pour un ou plusieurs objet directs.
Les objets directs (ou objets) sont des structures de données basiques, qui peuvent souvent être directement traduites vers un type d'objet primitif en Ruby (tableaux, booléens, dictionnaires, chaîne de caractères, entiers, objet nul, ...).
La plupart des objets directs de ce document seront des dictionnaires.
Les dictionnaires sont des séquences de clés et valeurs entourés de << et >>. Chaque clés type sa valeur. Les clés sont toutes des names objects (au format /Name).
Les éléments simples que vous voyez à l'écran lorsque vous visualisez un PDF sont en fait constitués d'une multitudes d'objets qui sont imbriqués et/ou qui se référencent. Les dictionnaires par exemple sont souvent imbriqués à de nombreux niveaux.
Les objets indirects peuvent se référencer les uns les autres. Une référence est un type d'objet. Elle se compose des numéros d'objet et de génération de l'objet référencé suivis du caractère R.
Ainsi, un objet indirect défini de la façon suivante :
2 0 obj
[Contenu]
endobjPourra être référencé (avant ou après sa définition dans le document) par : 2 0 R.
Ne pas confondre objet direct et indirect
Dans un fichier PDF, les objets peuvent être représentés de manière directe ou indirecte. Un objet direct est intégré directement dans le document et est souvent trouvé comme valeur d'une clé dans un dictionnaire ou comme élément dans un tableau. Il est accessible immédiatement sans référence externe. En revanche, un objet indirect est référencé par un identifiant unique (composé d'un numéro d'objet et d'un numéro de génération), ce qui permet au lecteur PDF de retrouver sa valeur en consultant d’autres parties du fichier. Les objets indirects facilitent la réutilisation et l'organisation des données dans un PDF en permettant de pointer vers un objet unique depuis plusieurs endroits.
Passons à la pratique.
Le catalogue
Le premier objet indirect contenu dans le corps est ici le catalogue. C'est l'objet racine du document. C'est un dictionnaire qui référence l'objet liste des pages.

Il peut contenir d'autres types d'objets. Il peut notamment contenir des actions javascript légitimes ou non.
Les actions javascript
Une action javascript est en réalité une série d'objets et peut prendre de multiples formes. Ici, action javascript désigne les différents types d'objets qui référencent une exécution de javascript (côté navigateur) conforme au format PDF et à son contenu. Ils correspondent à des utilisations non détournées de différents types d'objets. Ces objets peuvent être imbriqués.
Elles peuvent être contenues dans un dictionnaire de type /Action ou /OpenAction. La première est généralement attachée à une interaction de l'utilisateur comme un clic, la seconde s'exécute dès l'ouverture du document (pratique).

Ces objets peuvent aussi être définis indépendamment, les deux premiers sont alors simplement des dictionnaires qui référencent les suivants. L'objet /JS est contenu dans un objet indirect et contient directement le code à exécuter.

Retour au catalogue
Le catalogue peut contenir des actions javascript.

Ou les référencer.

Liste des pages
La liste des pages est un dictionnaire qui liste les références des pages (ses enfants) dans un tableau. Ici le tableau contient une seule entrée puisque le PDF que l'on écrit contient une seule page.
Les tableaux sont ouverts et fermés par [ et ], les différentes entrées sont séparées par des espaces.

S'il y avait plusieurs pages, les références seraient séparées par un simple espace : [ 3 0 R 4 0 R ]...
Page 1
Chaque page définit dans un dictionnaire Page les ressources nécessaires à son affichage : une police. La page référence aussi son contenu : ici l'objet identifié par la référence 4 0 R.
On peut y trouver des scripts ou des références à des scripts
Les polices peuvent être entièrement définies dans le PDF ou utiliser celles installées sur les ordinateurs (dans le premier cas, cela pourrait causer des problèmes d'affichage selon le lecteur)

Le stream
Dans un fichier PDF, un stream est un type d’objet utilisé pour stocker des données volumineuses ou complexes, comme des images, du texte formaté ou des informations graphiques. Il est délimité par les mots clés stream et endstream. Les streams permettent d’inclure des contenus plus longs ou compressés dans le fichier PDF, rendant ce type de données plus facile à gérer et à stocker de manière efficace.
Un stream commence généralement par une déclaration de ses propriétés dans un dictionnaire précédant le mot stream. Ce dictionnaire contient des informations essentielles, comme la longueur du stream (en octets) et, le cas échéant, la méthode de compression utilisée (par exemple, FlateDecode pour une compression zlib/deflate).
Voici un exemple simplifié d’un objet stream dans un fichier PDF (ici, aucune compression n'a été appliquée) :

Cet objet stream contient simplement du texte formaté à afficher.
Le texte est inséré entre les tags BT (Begin Text) et ET (End Text).
La première lignée définit la police : F1 (définie plus tôt) et la taille : 100 grâce au tag Tf (text font).
La deuxième ligne indique les coordonnées grâce au tag de dessin Td (text draw).
La dernière affiche le texte grâce à l'opérateur Tj (show text).
Les FontMatrix
Une FontMatrix est une matrice de transformation associée aux polices de caractères. Elle permet d'appliquer des transformations géométriques comme la mise à l'échelle, la rotation, la translation ou le cisaillement aux glyphes (caractères) d'une police avant leur affichage. Dans une FontMatrix, six valeurs numériques définissent ces transformations, offrant un contrôle précis sur la présentation des textes.
Dans un fichier PDF, les FontMatrix sont généralement des entrées dans un dictionnaire qui définit une police et un formatage.

La CVE-2024-4367
La faille découverte en mai 2024 exploite une faiblesse dans la gestion des FontMatrix par la bibliothèque PDF.js, permettant l’injection et l'exécution de code JavaScript malveillant.
Les valeurs contenues dans la FontMatrix étaient interprétées par PDF.js et évaluées pour afficher correctement la police. Si elles étaient remplacées par du code javascript, celui-ci était donc évalué.

Ce cas de figure sera traité de façon légèrement différente par le sanitizer : contrairement aux autres objets évoqués permettant des actions javascript, les FontMatrix n'ont en théorie, aucun rapport avec l'exécution de javascript. Elles peuvent donc être présentes dans de nombreux PDF sans qu'il ne soit pertinent de les supprimer.
Au lieu de retirer toutes les FontMatrix, nous testerons qu'elles sont au format correct (6 chiffres). Si elles ne le sont pas (si elles contiennent des caractères non numériques), elles seront retirées.
Fin de fichier
Le reste d'un fichier PDF contient des objets qui sont utiles pour permettre la lecture du fichier.
La table des références
La table des références (ou xref table) dans un fichier PDF est une structure qui répertorie les positions de tous les objets indirects en indiquant leurs décalages en octets par rapport au début du fichier.
La table des références est annoncée par le mot xref et doit commencer par une ligne contenant deux nombres séparés par un espace, représentant le numéro d'objet du premier objet de cette sous-section et le nombre d'entrées dans la sous-section.
xref
0 5 Ici, la table des références contient les objets indirects de 0 à 4.
Chaque ligne de la table des références fait 20 octets et contient :
nnnnnnnnnn ggggg m eolnnnnnnnnnn: l'offset en octet sur 10 chiffres de l'objet à partir du début du fichierggggg: le numéro de génération de l'objet sur 5 chiffres (à 65535 pour un objet libre)m: un mot clé sur une lettre qui indique si l'objet est libre (f) ou utilisé (n)eol: un marqueur de fin de ligne sur deux caractères
La table des références permet au lecteur PDF de localiser rapidement chaque objet sans devoir analyser l'ensemble du fichier. Placée vers la fin du document, cette table est essentielle pour que le lecteur puisse interpréter le document correctement et efficacement.
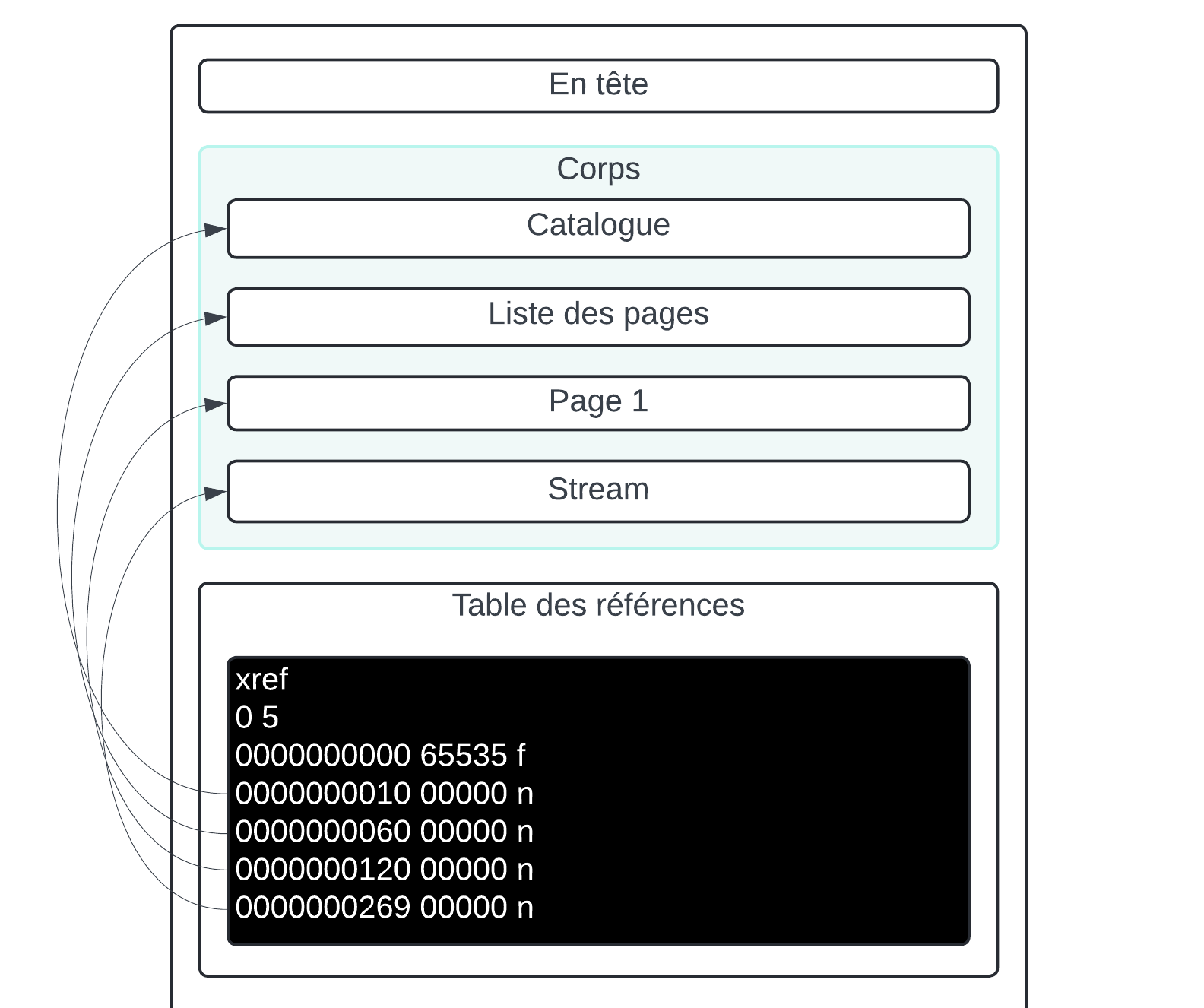
La table commence par un objet nul. Cet objet commence à l'offset 0. Comme il n'est pas utilisé son numéro de génération est à 65535 par convention, et le mot clé est f.
Les objets suivants sont les différents objets définis plus tôt, on ajoute pour chacun leur offset en octet depuis le début du fichier, leur numéro de génération, puis un n pour annoncé qu'ils sont utilisés.
Attention : Bien qu'elle s'appelle table des références, c'est techniquement une table de pointeurs.
Dans un PDF, une référence et un pointeur jouent des rôles distincts pour organiser et structurer les données.
Une référence est utilisée pour relier les objets entre eux au sein du fichier. Par exemple, un objet peut contenir une référence vers un autre objet indirect (identifié par un numéro d'objet et de génération, suivi de "R"), indiquant que son contenu est à rechercher ailleurs dans le document.
Un pointeur, quant à lui, indique une position précise dans le fichier PDF. Il est souvent employé dans la table des références (ou xref table) et dans le trailer pour diriger le lecteur PDF vers le début de chaque objet indirect. Le pointeur aide le lecteur à retrouver rapidement les éléments sans avoir à parcourir tout le fichier.
Ainsi, la référence est une relation logique entre objets, tandis que le pointeur est une adresse précise dans le fichier.
Le trailer
Les PDF doivent être lus en partant de la fin, c'est notamment le cas parce que le trailer, dernière section d'un fichier PDF, est le point d'entrée pour les lecteurs : il permet de trouver rapidement la table des références et l'emplacement de certains objets spéciaux.

Le trailer est un dictionnaire qui contient au moins deux entrées indispensables :
Une paire clé valeur /Root qui référence le catalogue.
Une paire clé valeur /Size qui annonce la taille de la table des références.
Enfin, le trailer contient également un pointeur vers la table des référence : le point d'entrée pour le lecteur qui interprétera le fichier.
Le marqueur de fin de fichier
La dernière ligne du fichier doit contenir uniquement le marqueur de fin de fichier, %%EOF.

Résumons
Et voilà ! Nous avons désormais construit un PDF infecté au js de toute pièce. Mais ça fait beaucoup d'informations. Voici quelques schémas pour résumer les différents objets et les relations qui les lient.
Les références
Les pointeurs
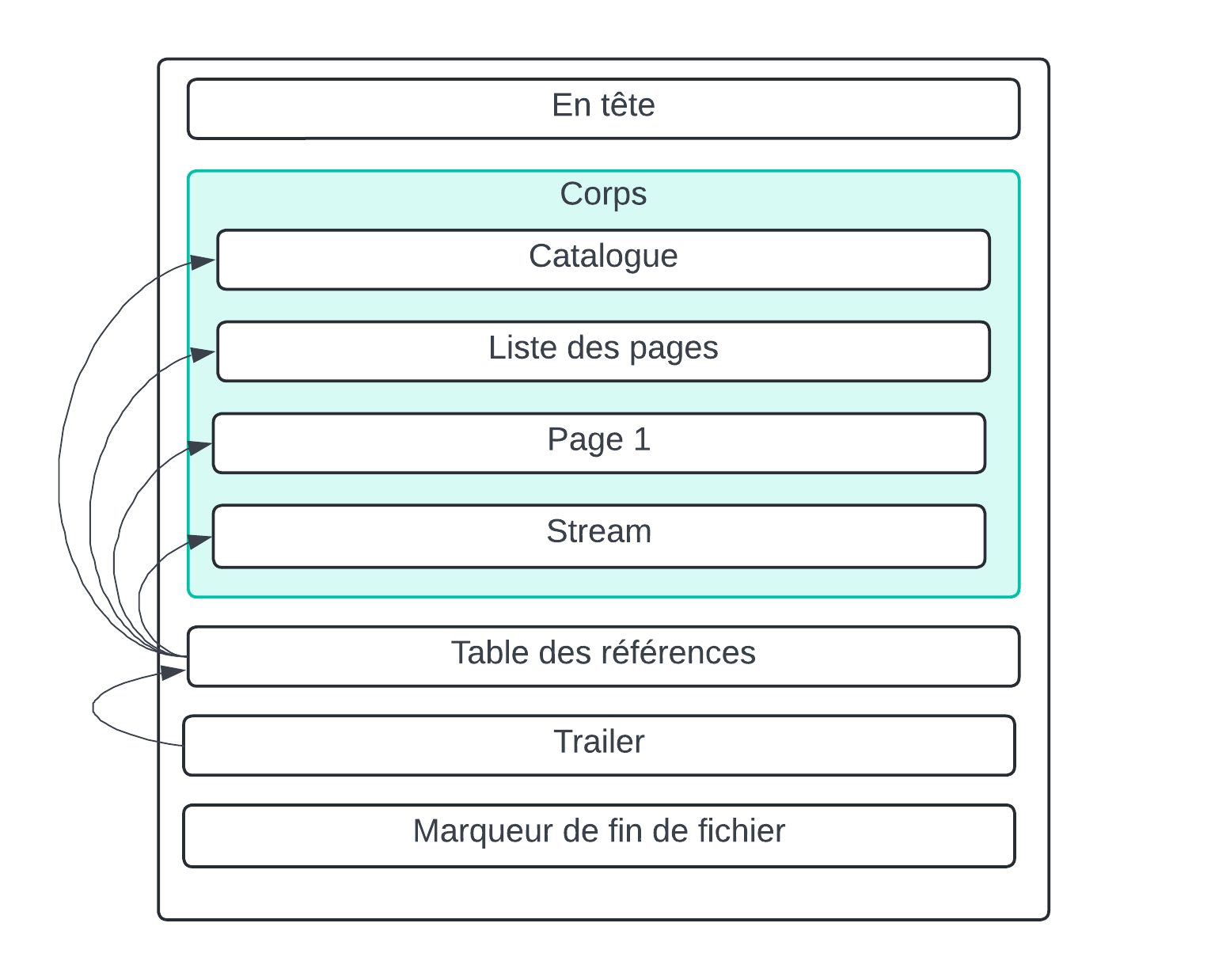
D'autres objets divers
Si de nombreux types d'objets peuvent être le point d'entrée à l'exécution de javascript, la plupart auront besoin d'un objet /JS qui contient le code. Supprimer cet objet s'il est présent permet donc de neutraliser de nombreux chemins d'exécution.
III - Maintenant, on nettoie tout ça
Notre PDF corrompu est prêt à servir de payload pour tester l'algorithme de nettoyage que nous allons coder.
L'algorithme est plutôt simple à réaliser : on fait la liste des types d'objets qui peuvent contenir du JS susceptible d'être exécuté et on les "désactive".
Donc, si on résume, deux cas de figure ont été abordés dans cet article :
Ceux qui sont normalement désactivés 99% du temps et qui sont conformes à ce qui est prévu par le format : ceux-ci reposent généralement sur un objet /JS. Supprimer la paire clé-valeur /JS - code
Les FontMatrix, dont on peut vérifier simplement qu'elles sont au format attendu et les supprimer si ce n'est pas le cas
HexaPDF
J'ai fait le choix de la gem HexaPDF pour coder mon sanitizer. Celle-ci est très bien codée et très utile pour les manipulations de PDF.
J'utilise pour l'exemple la gem Stringio pour gérer la sortie du document traité en mémoire plutôt que d'écrire directement sur le disque. C'est un choix qui m'a permis de simplifier l'intégration de ce sanitizer à mon application Rails.
Je présente ici un squelette simple pour le sanitizer, comme un script ruby indépendant afin de présenter la logique. Je vous laisse décider des détails d'implémentation.
On commence par importer les dépendances :
require 'hexapdf'
require 'stringio'Puis, on crée une classe qui servira de sanitizer, avec un peu de setup :
class Sanitizer
attr_reader :file_to_sanitize, :result
def initialize(file_to_sanitize)
@file_to_sanitize = file_to_sanitize
@result = { success: false, edited: false }
end
def call
open_pdf
sanitize_file
save_pdf
@result
end
def open_pdf
unless @file_to_sanitize && File.exist?(@file_to_sanitize) && File.extname(@file_to_sanitize).downcase == '.pdf'
print("File #{@file_to_sanitize} not found or not a PDF file\n")
exit(1)
end
@file = HexaPDF::Document.open(@file_to_sanitize)
endParcours du fichier
Il est ensuite possible de parcourir l'ensemble des objets contenus dans le PDF très simplement :
On vérifie si les objets rencontrés sont des dictionnaires, si c'est le cas, on appelle une fonction de nettoyage sur l'objet. HexaPDF gère de nombreux aspects de la logique de suppression : création d'un fichier en mémoire sans les objets supprimés, ajustement des offsets dans la table des références, etc. Ce qui permet de supprimer simplement des objets sans rentre le PDF invalide.
def sanitize_file
@file.each do |obj|
next unless obj.value.is_a?(Hash)
sanitize_object(obj)
end
endLa méthode sanitize_object(obj) délègue ensuite la responsabilité d'analyser et nettoyer les objets dictionnaires rencontrés aux méthodes appropriées :
Les FontMatrix corrompues (
remove_font_matrix)Les actions javascript, notamment l'objet /JS (
remove_js)
On écrira une dernière fonction qui parcourt récursivement les éventuels dictionnaires imbriqués pour s'assurer de nettoyer l'ensemble du document.
def sanitize_object(obj)
remove_font_matrix(obj) if obj[:Type] == :Font && (obj.key?(:FontMatrix) && corrupt_font_matrix?(obj))
remove_js(obj) if obj.key?(:JS)
clean_nested_dictionary(obj) if obj.is_a?(HexaPDF::Dictionary)
endLes actions javascript
def remove_js(obj)
print("Removing JS from object #{obj.oid}\n")
obj.delete(:JS)
@result[:edited] = true
endLes FontMatrix
Une première méthode cherche la façon dont la FontMatrix est insérée dans le dictionnaire de police (celle ci peut varier) puis on vérifie que la matrice ne contient que des valeurs numériques.
def corrupt_font_matrix?(obj)
font_matrix = obj[:FontMatrix].respond_to?(:value) ? obj[:FontMatrix].value : obj[:FontMatrix]
font_matrix.any? { |n| !n.is_a?(Numeric) }
endSi ce n'est pas le cas, on supprime complètement la matrice : puisqu'elle est corrompue, elle n'est pas utile.
def remove_font_matrix(obj)
print("Removing corrupt FontMatrix from object #{obj.oid}\n")
obj.delete(:FontMatrix)
@result[:edited] = true
endLe cas des dictionnaires imbriqués
Afin de nettoyer le code javascript même s'il est contenu dans une série de dictionnaires imbriqués, on écrit simplement une méthode récursive qui vérifie et nettoie les entrées d'un dictionnaires, et le contenu des entrées qui sont des tableaux.
def clean_nested_dictionary(dictionary)
return unless dictionary.is_a?(HexaPDF::Dictionary)
dictionary.each do |key, value|
if value.is_a?(HexaPDF::Dictionary)
sanitize_object(value)
clean_nested_dictionary(value)
end
next unless value.is_a?(Array)
value.each do |v|
next unless v.is_a?(HexaPDF::Dictionary)
sanitize_object(v)
clean_nested_dictionary(v)
end
end
endLe nettoyage est terminé !
On enregistre le fichier PDF s'il a été modifié, et on met à jour le hash de résultat du sanitizer.
def save_pdf
return unless @result[:edited]
@io = StringIO.new
@file.write(@io, optimize: false, validate: false)
@io.rewind
@result[:output_data] = @io.string
@result[:success] = true
endJe fais un petit main rapidement pour tester le sanitizer :
if __FILE__ == $0
if ARGV.empty?
puts 'Please provide the path to a PDF file to sanitize.'
exit
end
file_to_sanitize = ARGV[0]
sanitize = Sanitizer.new(file_to_sanitize)
result = sanitize.call
if result[:success]
File.open('sanitized_output.pdf', 'wb') { |f| f.write(result[:output_data]) }
puts "PDF sanitized successfully and saved as 'sanitized_output.pdf'."
else
puts 'PDF sanitization failed.'
end
endJe lance ça sur un fichier PDF contenant des actions JS et une FontMatrix corrompue :

Et j'obtiens un fichier PDF qui ne contient plus aucun code javascript. Il existe des reliques, comme cet objet indirect Javascript :
9 0 obj
<<
/S/JavaScript
>>
endobj
Ce pendant, la section /JS avec le code associé à l'action JavaScript ont été supprimés, il n'y a donc plus aucun risque d'exécution de code.
Quelques remarques pour la fin
L'exemple que nous avons vu ici est un cas de PDF extrêmement simple. En réalité un simple Hello World généré par un générateur de PDF moyen serait bien plus lourd et constitué de nombreux objets plus complexes.
Par exemple, nous avons fait appel dans notre document à la police Arial installée sur votre ordinateur, mais un Hello World en Arial généré par google docs contiendrait l'intégralité de la police afin de s'assurer que le PDF soit visualisé de façon exacte par n'importe quel ordinateur, même s'il n'a pas cette police installée.
Le format PDF permet d’inclure de nombreuses formes d'actions JavaScript qui n'ont pu être présentées en totalité dans cet article. Il est important de noter que ces actions sont destinées à être interprétées par des lecteurs PDF spécialisés (comme Adobe Acrobat).
Les navigateurs web ne permettent généralement pas cette exécution, et l’interprétation est propre à chaque bibliothèque ou lecteur de PDF.
Liens utiles :
A propos de cet article :
Le format PDF :
Let's write a pdf file : vulgarisation du format et de la syntaxe
Norme 32000-1:2008 ou PDF 1.7 : explications détaillées sur le format PDF
Les exploitations de PDF :
PDF files payload for pentesting : github avec différents fichiers PDF contenant du JS
Portable Data exFiltration: XSS for PDFs : aller plus loin sur les attaques XSS et les PDF
— Ines