
🍪🐘 Comprendre les index postgreSQL
Hello les petits Biscuits !
Bienvenue sur la 47ème édition de Ruby Biscuit.
Vous êtes maintenant 604 abonnés 🥳
Bonne lecture.
Vous lisez Ruby Biscuit, la newsletter Rails de Capsens. S’abonner gratuitement
Comment fonctionnent réellement les index d’une base de données postgreSQL ? Nous nous servons parfois des index avec la vague notion qu’ils accélèrent une requête. Je vais vous expliquer comment.
SQL utilise plusieurs stratégies pour trouver un objet dans une base de données. Parlons de deux stratégies particulières : la recherche séquentielle et la recherche par index.
Avant que nous ne définissions ces stratégies, il faut comprendre que les données d’une table en postgreSQL sont stockées dans un fichier qu’on appelle heap. Chaque objet a un rang avec les données correspondantes aux colonnes de la table, comme dans un fichier Excel. Les objets ne sont pas stockés dans un ordre particulier.
Recherche séquentielle
Prenons la requête :
SELECT "users".* FROM "users" WHERE (id = 1)Dans une recherche séquentielle, il faudra passer par chaque ligne du heap en demandant si l’objet stocké dans un rang de la table correspond à l’objet recherché. Comme vous pouvez l’imaginer, cette stratégie ne peut être efficace qu’avec un petit nombre d’objets, mais sera lente quand il y en aura beaucoup. D’ailleurs, la complexité d’une recherche séquentielle croît de façon linéaire à chaque nouvel objet qui est ajouté à la table.
Recherche par index
La recherche par index, comme son nom l’entend, fonctionne à l’instar de l’index d’un livre, où une table fait la correspondance entre un mot et des pages où ce mot apparaît. PostgreSQL utilise pourtant un système plus complexe que celui d’un index de livre. Alors qu’un livre utilise un seul index pour chercher des mots dans un texte, postgreSQL utilise plusieurs index organisés dans une arborescence pour chercher des données dans le heap.
Voici le schéma de ces index :
nœud racine => nœuds branche => nœuds feuille
Ce système d’organisation s’appelle un balanced tree. Il y a d’autres types d’index, mais nous nous concentrons sur les index de type balanced tree.
Le point d’entrée dans ces index imbriqués s’appelle le nœud racine. Vous pouvez imaginer un livre qui, plutôt que d’avoir un seul index, en aurait plusieurs, un pour les lettres de A à M et un autre pour les lettres de N à Z. Dans cette comparaison, ces deux index individuels correspondraient à des nœuds branche. Le nœud racine indiquerait sur quelles pages trouver chacun de ces deux index. Dans cet exemple, je parle de deux index seulement, mais dans une base de données postgreSQL, il peut, bien sûr, y avoir autant de nœuds branches que nécessaire pour structurer les données.
Le dernier niveau s’appelle le nœud feuille. Cela serait l’équivalent d’une page de l’un des index, où des mots sont listés avec les pages où l’on peut les trouver.
Maintenant que vous comprenez l’organisation de l’index, considérons comment la base de données exécutera une requête.
Reprenons cet exemple :
SELECT "users".* FROM "users" WHERE (id = 1)La table ci-dessous représente le nœud racine de l’index des identifiants de cette table. Itemoffset identifie les entrées. Ctid (current tuple ID) indique le numéro de page du nœud branche enfant. La colonne data représente la fourchette des données dans le nœud branche. Les data sont dans un format hexadécimal, mais je donne des entiers ici pour plus de clarté.
Dans cet exemple, le premier rang correspond à un nœud branche avec des identifiants de la table users d’une valeur de moins de 100. Le deuxième rang est pour un nœud branche avec des valeurs de 100 à 199, et le troisième rang est pour un nœud branche avec des valeurs supérieures ou égales à 200.
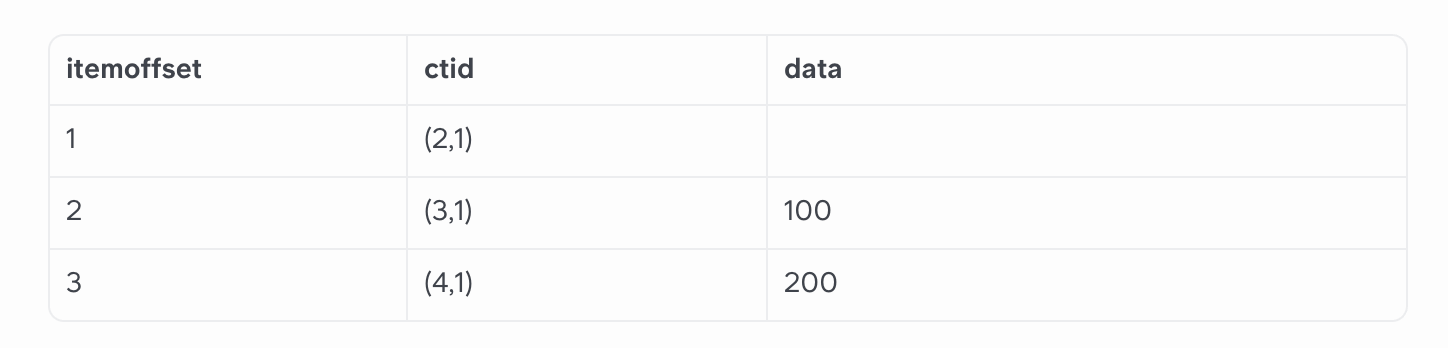
Quand la base de données lance une recherche par index, elle trouve la ligne correspondante en commençant au milieu de la liste. Elle se demande si la valeur est dans la première ou la deuxième moitié, choisit la bonne moitié et recommence le même processus de recherche binaire, jusqu’à ce qu’elle trouve le nœud branche correspondant. Le nœud branche lui-même ressemble structurellement au nœud racine. Des métadonnées font la distinction entre les branches et la racine.
Une fois que la recherche est au niveau du nœud branche, elle fait une autre recherche binaire, jusqu’à ce qu’elle trouve le nœud feuille, lequel contient la liste des valeurs individuelles de la colonne indexée, ainsi que le current tuple ID qui permet de trouver l’objet recherché dans le heap. Alors que dans le nœud racine et le nœud branche, le ctid n’indique qu’une page, dans le nœud feuille la paire de valeurs, page et itemoffset, désigne l’emplacement exact de l’objet dans le heap.

Quand nous ajoutons un index à une colonne de notre base de données, cette dernière construit les nœuds feuille, nœuds branche et le nœud racine nécessaires pour trouver un objet avec une recherche par index.
Si la complexité des recherches séquentielles croît de façon linéaire avec l’ajout de nouveaux objets à une table, la complexité d’une recherche par index croît de façon logarithmique. Cette différence est due au fait qu’une recherche par index navigue entre une série de nœuds dont les données sont ordonnées et donc faciles à trouver, alors qu’une recherche séquentielle passe ligne par ligne sur les données du heap. Imaginez la différence de complexité entre chercher un mot dans un dictionnaire dont les entrées sont organisées alphabétiquement et chercher un mot dans un dictionnaire sans ordre aucun.
Même si l’index peut accélérer une recherche, il faut savoir qu’à la création, la mise à jour et la suppression d’un objet, la base de données doit modifier les index imbriqués, afin de maintenir les données.
Comment est-ce que SQL choisit la bonne méthode de recherche ?
SQL sait choisir la méthode la plus efficace pour la requête demandée. Nous pouvons même lui demander quelle stratégie il va choisir avec EXPLAIN ou avec EXPLAIN (ANALYZE). EXPLAIN tout court explique la stratégie de requête ; EXPLAIN (ANALYZE) explique et exécute la requête.
EXPLAIN SELECT "users".* FROM "users" WHERE "users"."id" = 1La base de données répondra avec soit Seq Scan, soit Index Scan, ainsi que des informations concernant le « coût » d’une requête.
Ce résultat peut être paradoxal. Même une colonne indexée peut faire l’objet d’une requête séquentielle. Cela peut arriver pour plusieurs raisons. Si, par exemple, le nombre d’objets est petit, comme cela est souvent le cas en local, une requête séquentielle reste préférable.
EXPLAIN SELECT "users".* FROM "users" WHERE "users"."id" = 1 En local, où j’ai moins de 100 utilisateurs, SQL répond :
Seq Scan on users (cost=0.00..4.45 rows=1 width=757)mais dans la base de données de production, la réponse est :
Index Scan using users_pkey on users (cost=0.29..8.30 rows=1 width=757)Une recherche séquentielle est également préférable si une grande partie des objets d’une table doit être trouvée. Par exemple :
EXPLAIN SELECT "users".* FROM "users" WHERE "users"."id" > 1retourne
Seq Scan on users (cost=0.00..1719.10 rows=19127 width=757)Comme presque tous les utilisateurs sont demandés par cette requête, utiliser l’index pour trouver des utilisateurs individuellement n’est pas aussi efficace qu’une recherche séquentielle.
PostgreSQL choisit la stratégie de recherche la moins coûteuse en analysant des données qu’il garde en mémoire, telles que le nombre de lignes et la fourchette des valeurs.
Quel est le gain de temps réel de l’ajout d’un index ?
Jusqu’ici, nous avons regardé la recherche d’un utilisateur par son identifiant, qui est une colonne indexée de facto dans notre base de données.
SELECT "users".* FROM "users" WHERE (id = 1)Regardons maintenant la colonne first_name, qui n’est pas indexée. Avec une base de données contenant 100.000 utilisateurs, combien de temps faudra-t-il pour faire la requête suivante avec une recherche séquentielle ?
EXPLAIN (ANALYZE) SELECT "users".* FROM "users" WHERE "users"."first_name" = 'John'Comme nous l’avons vu, EXPLAIN (ANALYZE) expliquera la stratégie de requête et l’exécutera. Voici le résultat :
Seq Scan on users (cost=0.00..1925.58 rows=1 width=728) (actual time=0.036..15.707 rows=1.00 loops=1)
Filter: ((first_name)::text = 'John'::text)
Rows Removed by Filter: 100036
Buffers: shared hit=1726
Planning Time: 0.190 ms
Execution Time: 15.748 ms
(6 rows)Il faut 15,748 millisecondes pour exécuter cette requête.
Qu’est-ce qui se passera si nous indexons la colonne users.first_name ?
Index Scan using index_users_on_first_name on users (cost=0.42..8.44 rows=1 width=944) (actual time=0.032..0.032 rows=1.00 loops=1)
Index Cond: ((first_name)::text = 'John'::text)
Index Searches: 1
Buffers: shared hit=4
Planning Time: 0.133 ms
Execution Time: 0.070 ms
(6 rows)Nous passons de 15,748 millisecondes à 0,070 millisecondes. La requête est à peu près 224 fois plus rapide.
Les index sur plusieurs colonnes
Il est également possible d’ajouter un index sur plusieurs colonnes. Prenons l’exemple suivant où nous cherchons un utilisateur par son prénom et son nom.
SELECT "users".* FROM "users" WHERE "users"."first_name" = 'John' AND "users"."last_name" = 'Doe'Plutôt que first_name_index tout court, nous pouvons créer un first_name_last_name_index. Comme vous le voyez dans le schéma ci-dessous, le nœud racine et les nœuds branche ordonnent les données selon la première colonne de l’index, first_name dans notre exemple. C’est dans le nœud feuille qu’apparaissent les données de last_name.
L’index first_name_last_name_index nous permettra de faire notre requête, puisque la base de données peut chercher par prénom dans un premier temps et ensuite par nom, une fois qu’elle aura trouvé le bon prénom dans le nœud feuille. Nous pourrions même utiliser cet index pour chercher par prénom uniquement, car la base de données peut se limiter à trouver toutes les occurrences d’un prénom dans le nœud feuille, sans s’occuper des noms de famille.
SELECT "users".* FROM "users" WHERE "users"."first_name" = 'John'En revanche, cet index ne permet pas de chercher par nom de famille seul : comme les entrées sont ordonnées par prénom, les noms de famille identiques sont dispersés dans toutes les feuilles.

Où faut-il ajouter des index ?
Maintenant que vous comprenez mieux le processus de recherche par index, vous pouvez indexer les colonnes de façon plus efficace. Outre les clefs étrangères que nous avons besoin de rechercher, il peut être utile d’indexer des colonnes consacrées aux données d’un service externe. Si, par exemple, vous recevez et stockez un identifiant d’une API externe, lors de la création d’un objet chez ce dernier, et que vous avez besoin de faire des recherches par cet identifiant, il faut préférer un index.
Toutefois, il n’est pas idéal d’ajouter des index partout, puisque la construction et la maintenance de l’arborescence des index avec leurs différents nœuds sont coûteuses. Comme nous l’avons vu, un index peut accélérer considérablement une requête, mais cette accélération n’est utile que si l’index est utilisé.
Il faut également comprendre que les index peuvent être inutiles dans certains cas. Nous avons déjà vu que la requête
EXPLAIN SELECT "users".* FROM "users" WHERE "users"."id" > 1sera exécutée avec une recherche séquentielle, car elle sort une grande partie des utilisateurs. Cet exemple n’est certes pas très réaliste. Imaginons plutôt que nos utilisateurs ont un état.
EXPLAIN SELECT "users".* FROM "users" WHERE "users"."state" = 'approved' Même si nous faisons fréquemment des recherches sur la colonne state, l’indexer n’est pas utile si certains états peuvent représenter une grande partie des utilisateurs.
Enfin, une requête qui transforme les données telles qu’elles se trouvent dans les différents nœuds d’un index sera exécutée avec une recherche séquentielle. Prenons la requête
SELECT "users".* FROM "users" WHERE (Lower(first_name) = 'john')Lower(first_name) transforme la donnée brute de first_name telle qu’elle est structurée dans l’index, ce qui rend cet index inexploitable dans ce cas.
— Andrew, développeur chez Capsens