
🍪🏭 ActiveRecord : Comment on éviter les pièges de performance en production
Temps de lecture : 5 minutes
Hello les petits Biscuits !
Bienvenue sur la 31ème édition de Ruby Biscuit.
Vous êtes maintenant 575 abonnés 🥳
Maintenant Ruby biscuit, c’est aussi votre meilleur allié pour recruter des devs Ruby !
Si vous n’avez pas encore rejoint le club, RDV sur https://recrutement.rubybiscuit.fr
Bonne lecture.
ActiveRecord : Éviter les pièges de performance en production
Récemment, en ajoutant une fonctionnalité de génération d’échéancier à l’une de nos applications Rails, je me suis retrouvée face à un problème de performance.
Notre système fonctionne ainsi : un projet est publié, des investisseurs y investissent et en retour, ils perçoivent un remboursement avec un taux d’intérêt. Du crowdfunding globalement. Pour aider les administrateurs à organiser ces remboursements, nous devons générer un échéancier pour chaque investisseur, souvent étalé sur plusieurs mois, voire plusieurs années.
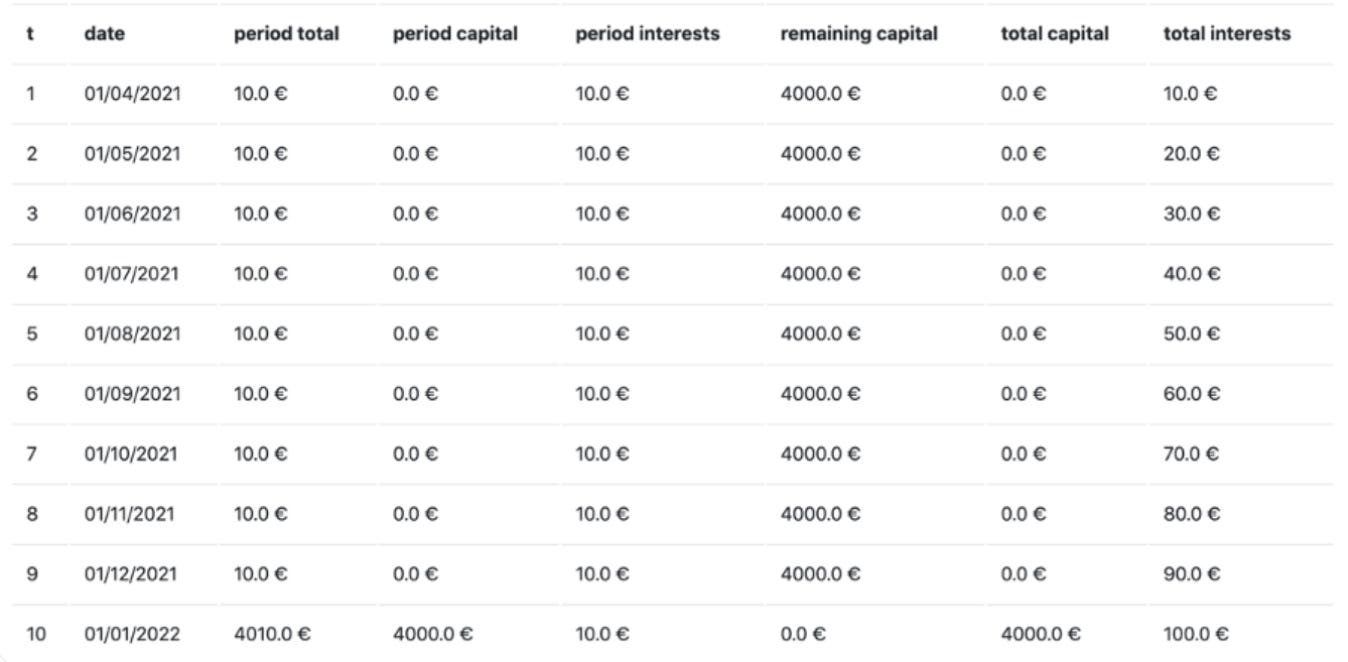
Pour vous donner une idée, dans mon cas, il s'agissait d’environ 5 000 investisseurs, chacun ayant un échéancier sur 30 mois, soit un total de 150 000 échéances à calculer et générer.
J’ai donc codé ma fonctionnalité tranquillement, testé son bon fonctionnement, puis ouvert ma pull request (merge request sur GitLab) en attendant sa relecture.

Tout allait bien jusqu'à ce que mon relecteur pose la question qui fâche : "Tu as testé ton script avec des volumes similaires à ceux de la production ?"
La réponse était évidente : "Non."
Je m’y mets donc… et là, catastrophe. Mon service met plusieurs minutes à s’exécuter. C’est interminable. Pourtant, j’avais fait attention à la performance… du moins c’est ce que je croyais.
Il faut donc remettre les mains dans le cambouis. C’est parti !
Si vous voulez suivre en détail la suite de l’article, vous pouvez cloner ce repo :
👉 https://github.com/CapSens/ruby-biscuit-active-record-performance.git
Il contient une version ultra simplifiée de notre problématique du jour.
Notre domaine étant le crowdfunding, certaines logiques métier peuvent vous être inconnues. Voici quelques éléments essentiels pour ne pas vous perdre :
Un échéancier doit pouvoir être généré ou regénéré à tout moment. Avant d’en générer un nouveau, il est donc essentiel de supprimer l’ancien.
Un projet est géré par un porteur de projet, qui doit rembourser ses investisseurs en répartissant une somme précise incluant des intérêts, selon un nombre d’échéances défini contractuellement. Ces échéances sont appelées
borrower_terms.Les échéances perçues par les investisseurs (les remboursements qu’ils reçoivent) sont quant à elles appelées
lender_terms.
Mise en place d'un script de benchmark
Un benchmark est un test qui permet de mesurer la rapidité et l'efficacité de notre code.
Il existe différents outils pour cela, plus ou moins puissants selon les besoins. L’important est de choisir celui qui s’adapte le mieux à votre cas d’usage.
Ma démarche à été la suivante :
Mettre en place un script de benchmark simple, que je pourrais relancer après chaque modification du code.
Tester différentes optimisations pour gagner en performance et identifier des quick wins.
Pour notre script de benchmark, nous avons décidé d’implémenter deux méthodes :
benchmark_memory: utilise la gembenchmark_memorypour évaluer la quantité de mémoire utilisée par notre code et détecter les fuites mémoire (ce qui n’est pas libéré).benchmark_time: une méthode custom qui mesure le temps d’exécution du code.
Ces deux méthodes prennent en paramètre : le nombre de souscriptions et le nombre d’échéances souhaitées
À chaque appel de ces méthodes :
Un jeu de données est généré.
Deux générateurs d’échéanciers sont lancés :
L’un avec la version initiale du code
L’autre avec la version améliorée
Cela permet d’observer les gains de performance sans modifier le code originel.
Tout cela s’exécute dans une transaction Active Record, ce qui permet de revenir facilement à l’état initial après chaque test.
Dans le repo, vous trouverez le script de benchmark ici : app/scripts/test_script.rb.
Et voici le code de génération de l’échéancier :

Spoiler alert : J'ai réussi à diviser le temps d'exécution par ~ 6 et la mémoire utilisée par ~ 3.
Ci dessous quelques exemples de benchmark fait durant l'optimisation :

Ici on peut voir qu'entre le code originel et la version améliorée on a diminué presque par 6 le temps en millisecondes
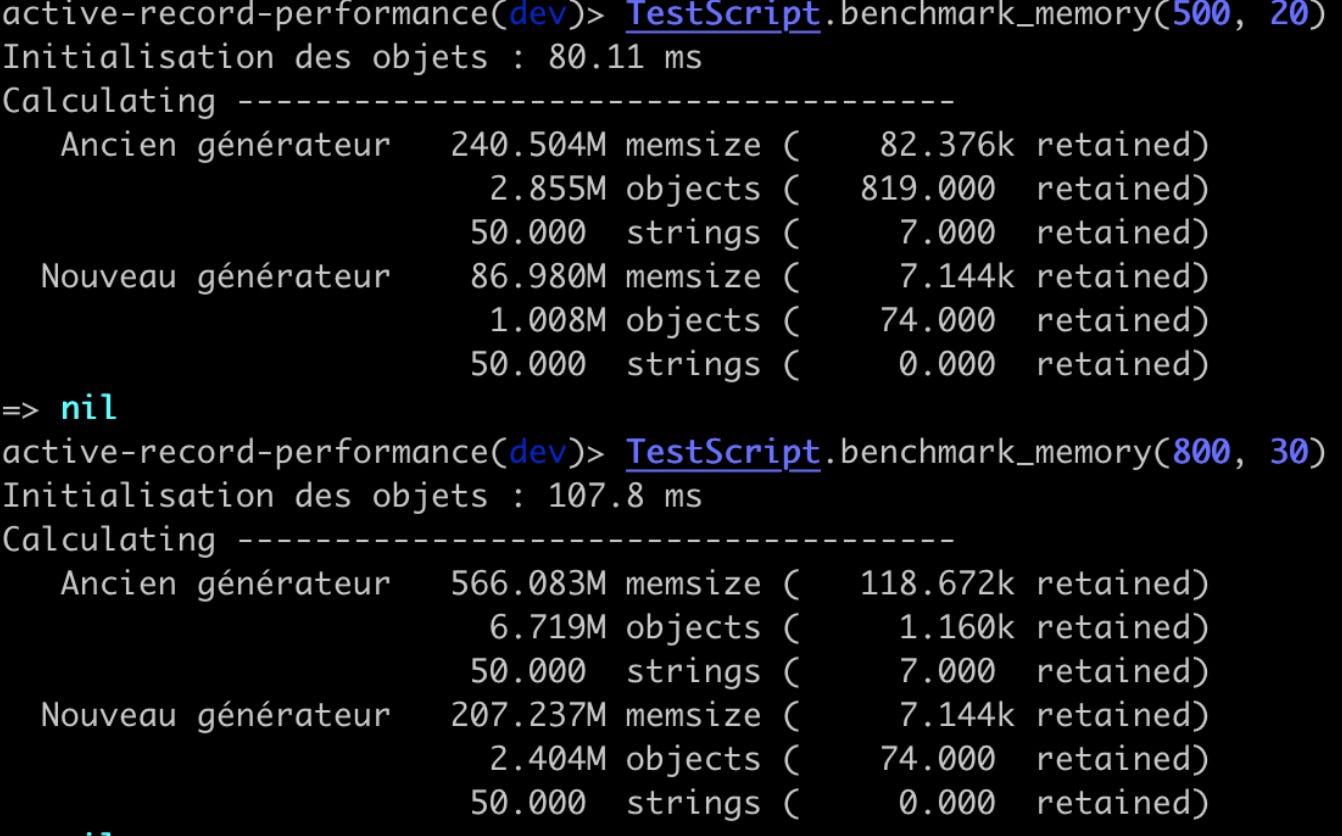
Ici dans le premier exemple on divise par 3 la taille de la mémoire et le nombre d'objets en mémoire
Pas mal non ? Allons voir ce que j'ai modifié !
Les améliorations
destroy_allvsdelete_allincludesor notincludesfind_eachvseachactiverecord-import
Mesurer le temps d’exécution global, c’est bien, mais comprendre quels morceaux du code sont les plus lents, c’est mieux. C’est en analysant l’exécution étape par étape que l’on identifie où les améliorations sont nécessaires.
Une bonne pratique à adopter est d'ajouter des messages de debug aux différentes étapes de votre script. Cela permet d’observer quelles parties prennent le plus de temps et ou des optimisations sont possibles.
1️⃣ destroy_all vs delete_all
J’ai commencé par ajouter un message de debug qui m’indiquait à chaque fois qu’une échéance était générée. À ma grande surprise, j’ai attendu plusieurs minutes avant que la toute première échéance apparaisse.
Le problème : un destroy_all trop gourmand
En y regardant de plus près, j’ai compris pourquoi. Avant de générer les nouvelles échéances, mon script supprimait les anciennes avec destroy_all.
Supprimer 150 000 échéances avec destroy_all déclenchait les callbacks Rails sur chaque suppression. Même si chaque suppression ne prenait que 0.001 seconde, cela représentait déjà 150 secondes d’attente avant même de commencer à générer de nouvelles échéances 😮💨.
En remplaçant destroy_all par delete_all, j’ai drastiquement réduit le nombre de requêtes SQL. On est passé de 150 000 requêtes à une seule.
Attention : destroy_all reste utile lorsque vous avez besoin de déclencher des callbacks de suppression, notamment pour gérer les objets associés. Ce n’est donc pas une méthode à systématiquement remplacer par delete_all, mais dans mon cas, l’optimisation était pertinente.
2️⃣ includes or not includes
Lorsque l'on manipule un grand nombre de données, il est essentiel de bien gérer le chargement des ressources. Sinon, on risque de multiplier inutilement les requêtes SQL, ce qui peut rapidement dégrader les performances.
Le problème : N+1
Prenons un extrait de la version non optimisée du code :
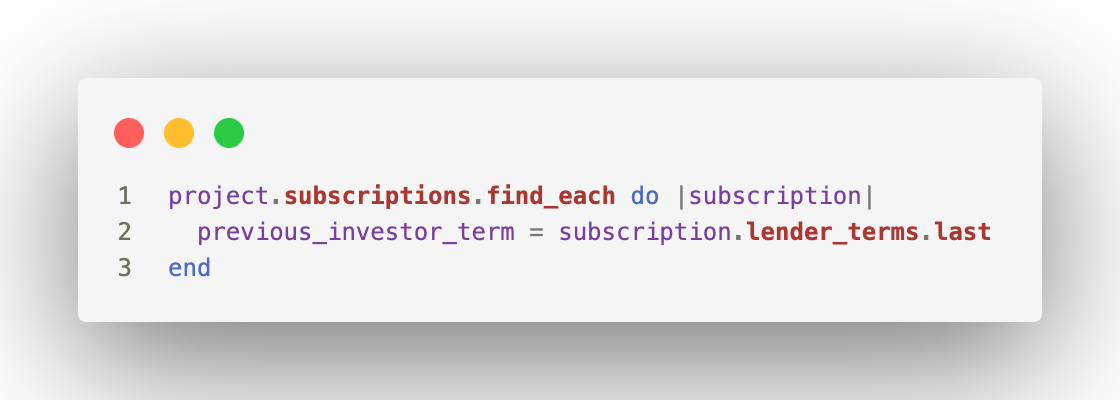
Dans un premier temps, on récupère les souscriptions avec find_each, qui charge les données par batchs de 1 000, ce qui est déjà une bonne pratique.
Mais ensuite, pour chaque souscription, on récupère la dernière échéance via subscription.lender_terms.last, ce qui génère une requête supplémentaire par souscription.
Si on a 5 000 souscriptions, on se retrouve donc avec :
5 requêtes pour charger les souscriptions (
find_eachtraite 1 000 éléments à la fois)5 000 requêtes pour récupérer les échéances
Soit un total de 5005 requêtes SQL...
Comment arranger ça ? En utilisant includes(:lender_terms), on demande à Active Record de récupérer les échéances en une seule requête par batch :
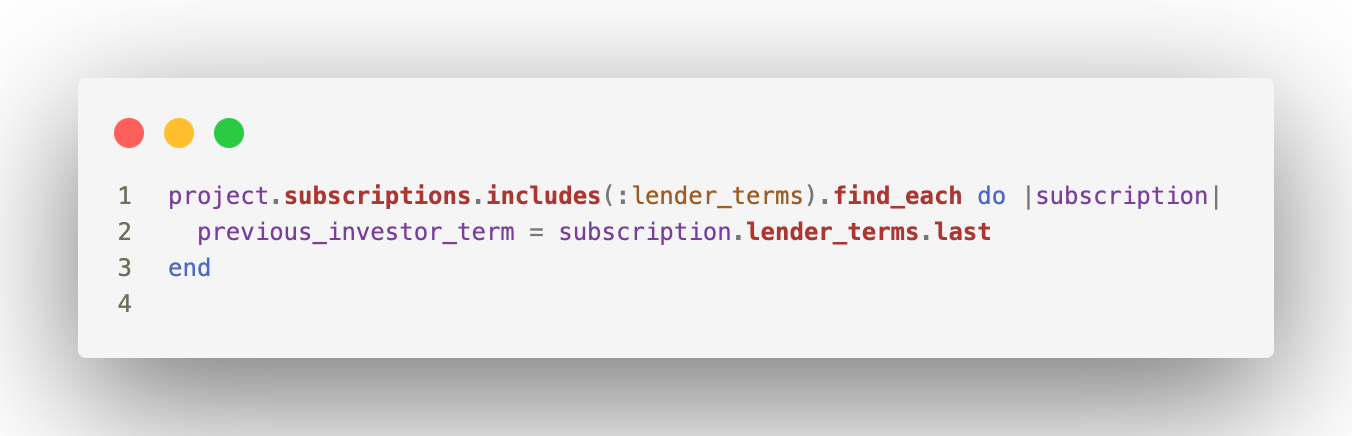
Nous avons maintenant : 5 requêtes avec le find_each (5*1000) + 1 requêtes par batch pour récupérer les échéances, soit 10 requêtes SQL contre 10 000 dans la version initiale 😵.
3️⃣ find_each vs each
Reprenons notre exemple project.subscriptions.find_each, si on remplace le find_each par un each on se retrouve à charger en mémoire un array avec 5 000 objets ruby, ça fait beaucoup pas vrai ?
En utilisant find_each, par défaut on aura des batchs de 1 000 donc on chargera en mémoire que 1 000 objets ruby. Ce qui est déjà correcte, surtout dans notre cas ou ca ne nécessitera que 5 requêtes au total.
C'est génial, on l'utilise partout alors ! ...Pas vraiment si on regarde le bout de code suivant
borrower_terms = project.borrower_terms
project.subscriptions.find_each do |subscription|
previous_investor_term = subscription.lender_terms.last
current_investor_term = nil
borrower_terms.find_each do |borrower_term| # <--
end
end
Vous ne le voyez peut-être pas mais c'est contre productif à la ligne borrower_terms.find_each. Pourquoi ?
La variable borrower_terms est déjà récupéré plus haut et elle sera la même pour l'itération de chaque souscription, le problème c'est que le find_each déclenche une nouvelle requête SQL à chaque fois alors que la donnée n'a pas changé. On fait donc plusieurs fois 5*1000 requêtes, au lieu de le faire 1 seul fois.
La solution ici est simple, utilisé .each qui nous permet d'itérer sans faire de requête supplémentaire car les ressources sont déjà chargées.
A savoir : find_each permet de faire des batch mais supprime également toute notion d'ordre dans la requête initiale. Il est important de l'avoir en tête et de ne pas l'utiliser si l'ordre de vos resources est important.
4️⃣ activerecord-import
activerecord-import est une superbe gem qui nous permet de créer plusieurs ressources en une seule requête. Je vous invite à y jeter un oeil si vous manipulez beaucoup de données ou que vous faîtes beaucoup de migrations.
Pas besoin d'explication très détaillée, avec plus de 150 000 échéances à créer, ça ne peut qu'améliorer la performance de notre code. Si on revient en arrière sur le premier point concernant la suppression des échéances c'est un peu le même principe, pourquoi s'embêter à faire autant de requêtes qu'il y a de ressources alors qu'on pourrait le faire en faire une seule.
Pour conclure j'ajouterai à tout cela, qu'il est important, dans cette méthode de test avec un benchmark, de ne pas sous estimer le temps d'affichage des logs. Pour se rapprocher du temps réel d'exécution il faudra penser à retirer les logs, vous pouvez le faire facilement avec la commande ActiveRecord::Base.logger = nil
La performance dans une application est un sujet passionnant et très très vaste. Bien qu'il soit toujours important de bien connaitre son outil de travail pour éviter certains écueils, il faut aussi garder en tête que plus on avance dans l'optimisation plus le rapport temps passé / gain est faible. Heureusement pour nous, la communauté Ruby est très active sur le sujet et beaucoup de recherches sont menées, notamment chez Shopify pour améliorer les performances de notre langage préféré.
Internet regorge d'articles sur ces travaux alors si vous avez les reins solides n'hésitez pas à vous plonger dans le sujet.
Une liste d'outils interéssants pour optimiser vos applications
ActiveRecord :
Importer des records en masse : https://github.com/zdennis/activerecord-import
Traquer les N+1 : https://github.com/flyerhzm/bullet
Mémoire / CPU :
Profiler ruby : https://github.com/tmm1/stackprof
Similaire au module Benchmark mais pour la mémoire : https://github.com/michaelherold/benchmark-memory
Un benchmark mémoire un peu plus complet fait par thoughtbot : https://github.com/SamSaffron/memory_profiler
RSpec :
Une boite à outil pour améliorer la performance de votre suite de test : https://github.com/test-prof/test-prof
— David & Quentin
Sujet super intéressant ! Merci pour le partage